
Jonathan Frankle
MIT CSAIL
jfrankle@csail.mit.edu
Michael Carbin
MIT CSAIL
mcarbin@csail.mit.edu
ニューラルネットワークの枝刈り技術は、学習済みネットワークのパラメータ数を90%以上削減し、精度を損なうことなくストレージ要件を削減し、推論の計算性能を向上させることができる。しかしながら、現状では、枝刈りによって生成される疎な構造は最初から学習は困難であり、同様に学習性能を向上させることが困難であることが分かっている。
標準的な枝刈り手法により、初期化によって効果的にトレーニングできるサブネットワークが自然に発見されることが分かった。これらの結果に基づいて、宝くじ仮説を明確にする。つまり、高密度でランダムに初期化されたフィードフォワード ネットワークには、単独でトレーニングすると、同様の反復回数で元のネットワークに匹敵するテスト精度に達するサブネットワーク (当りくじ) が含まれる。我々が見つけた当りくじは初期化宝くじに当選したものであり、その接続にはトレーニングを特に効果的にする初期重みがある。
当りくじを識別するアルゴリズムと、宝くじ仮説とこれらの偶然の初期化の重要性を裏付ける一連の実験を紹介する。MNIST および CIFAR10 のいくつかの完全接続型および畳み込みフィードフォワード アーキテクチャのサイズの 10 ~ 20% 未満の当りくじを一貫して見つける。このサイズを超えると、見つけた当りくじは元のネットワークよりも速く学習し、より高いテスト精度を達成する。
ニューラル ネットワークから不要な重みを削除する (プルーニング) 手法 (LeCun 他、1990 年、Hassibi & Stork、1993 年、Han 他、2015 年、Li 他、2016 年) により、精度を損なうことなくパラメーター数を 90% 以上削減できる。これにより、トレーニング済みネットワークのサイズ (Han 他、2015 年、Hinton 他、2015 年) またはエネルギー消費量 (Yang 他、2017 年、Molchanov 他、2016 年、Luo 他、2017 年) が削減され、推論の効率が向上する。ただし、ネットワークのサイズを縮小できるのであれば、トレーニングの効率化のために、このより小さなアーキテクチャをトレーニングしないのはなぜだろうか?最近の知見では、枝刈りによって発見されたアーキテクチャは最初からトレーニングするのが難しく、元のネットワークよりも精度が低くなる。1
1「枝刈りモデルを最初からトレーニングすると、枝刈りモデルを再トレーニングするよりもパフォーマンスが低下する。これは、容量の小さいネットワークをトレーニングするのが難しいことを示している可能性がある。」(Li et al., 2016)「再トレーニング中は、枝刈りを生き残った接続の初期トレーニング フェーズからの重みを保持する方が、枝刈りされたレイヤーを再初期化するよりも優れている...勾配降下法は、ネットワークが最初にトレーニングされたときには適切な解を見つけることができるが、一部のレイヤーを再初期化して再トレーニングした後はそうではない。」(Han et al., 2015)
例を考えてみよう。図1 では、MNIST の完全接続ネットワークと CIFAR10 の畳み込みネットワークからサブネットワークをランダムにサンプリングしてトレーニングしている。ランダム サンプリングは、LeCun ら (1990) と Han ら (2015) が使用した非構造化枝刈りの効果をモデル化する。さまざまなスパース レベルにわたって、破線は最小検証損失 2 の反復とその反復でのテスト精度をトレースする。ネットワークがスパースであるほど、学習が遅くなり、最終的なテスト精度は低くなる。
2 ネットワークの学習速度の代理として、早期停止基準がトレーニングを終了する反復を使用する。この論文全体で採用している特定の早期停止基準は、トレーニング中の検証損失が最小となる反復である。この選択の詳細については、付録 C を参照。
図1: さまざまなサイズで開始してトレーニングした場合の、MNIST の Lenet アーキテクチャと CIFAR10 の Conv-2、Conv-4、および Conv-6 アーキテクチャ (図2 を参照) の早期停止が発生する反復 (左) とその反復でのテスト精度 (右)。破線はランダムにサンプリングされたスパース ネットワーク (10 回の試行の平均) 。実線は当りくじ (5 回の試行の平均)。
本論文では、最初から訓練を行い、大規模なネットワークと同等以上の速度で学習し、同等のテスト精度を達成する小規模なサブネットワークが一貫して存在することを示す。図1の実線は、我々が発見したネットワークを示す。これらの結果に基づき、宝くじ仮説を提唱する。
宝くじ仮説。ランダムに初期化された高密度ニューラルネットワークには、単独でトレーニングした場合、最大で同じ回数の反復トレーニングを行った後、元のネットワークのテスト精度に匹敵するように初期化されたサブネットワークが含まれている。
より正式には、初期パラメータが\(\theta =\theta_0~\mathcal D_\theta\)である密なフィードフォワードニューラルネットワーク\(f(x; \theta)\)を考える。訓練データに対して確率的勾配降下法(SGD)を用いて最適化を行うと、\(f\)は反復回数\(j\)において最小の検証損失\(l\)に達し、テスト精度は\(a\)となる。さらに、パラメータにマスク\(m\in\{0,1\}^{|\theta|}\)を適用し、初期値が\(m\odot\theta_0\)となるように訓練データ\(f(x;m\odot\theta)\)を学習させる場合を考える。同じトレーニングセット(\(m\)を固定)でSGDを用いて最適化すると、\(f\)は反復回数\(j'\)で最小の検証損失\(l'\)に達し、テスト精度は\(a'\)となる。宝くじ仮説は、\(j'\leq j\)(トレーニング時間は同じ)、\(a'\geq a\)(精度は同じ)、および\(||m||_0\ll |\theta|\)(パラメータが少ない)となる\(\exists m\)が予測される。
標準的な枝刈り手法を用いることで、全結合型および畳み込みフィードフォワード型ネットワークから、このような学習可能なサブネットワークを自動的に発見できることを発見した。これらの学習可能なサブネットワークを、学習可能な重みと接続の組み合わせを持つ初期化の抽選に当選したため、「当りくじ」と名付けた。これらのパラメータをランダムに再初期化すると(\(f(x;m\odot\theta'_0)\)、つまり\(\theta'_0\sim\mathcal D_\theta\))、当りくじは元のネットワークのパフォーマンスに匹敵しなくなる。これは、これらの小規模ネットワークは適切に初期化されない限り効果的に学習できないという証拠となる。
当りくじの特定。ネットワークを学習させ、最小値の重みを枝刈りすることで、当りくじを特定する。残りの枝刈りされていない接続が当りくじのアーキテクチャを構成する。本研究の特徴として、枝刈りされていない各接続の値は、学習前の元のネットワークの初期値にリセットされる。これが我々の中心的な実験結果である。
説明したように、この枝刈りアプローチはワンショットである。ネットワークは一度トレーニングされ、重みの \(p\)% が枝刈りされ、生き残った重みがリセットされる。ただし、この論文では、ネットワークを \(n\) ラウンドにわたって繰り返しトレーニング、枝刈り、リセットする反復枝刈りに焦点を当てている。各ラウンドでは、前のラウンドで生き残った重みの \(p^{\frac{1}{n}}\)% が枝刈りされる。我々の結果は、反復枝刈りは、ワンショット枝刈りよりも小さいサイズで元のネットワークの精度に一致する当りくじを見つけることを示している。
結果:MNISTの全結合アーキテクチャとCIFAR10の畳み込みアーキテクチャにおいて、ドロップアウト、重み減衰、バッチ正規化、残差接続などの手法を用いて、複数の最適化戦略(SGD、モメンタム、Adam)にわたって当りくじを特定した。非構造化枝刈り手法を用いるため、これらの当りくじはスパースである。より深いネットワークでは、枝刈りに基づく当りくじ発見戦略は学習率に敏感であり、高い学習率で当りくじトを見つけるにはウォームアップが必要となる。発見した当りくじは、元のネットワーク(より小さいサイズ)の10~20%(またはそれ以下)のサイズである。このサイズまで縮小すると、元のネットワークのテスト精度(同等の精度)と同等かそれを超える反復回数(同等の学習時間)に達する。ランダムに再初期化すると、当りくじのパフォーマンスははるかに低下するため、構造だけでは当りくじの成功を説明できないことを意味する。
宝くじ予想。動機付けの問いに戻り、我々は仮説を拡張し、SGDが適切に初期化された重みのサブセットを探し出し、学習するという未検証の予想を提示する。密でランダムに初期化されたネットワークは、枝刈りによって得られる疎なネットワークよりも学習が容易である。これは、学習によって当りくじを復元できる可能性のあるサブネットワークの数が多いためである。
貢献
示唆:本論文では、宝くじ仮説を実証的に検証する。当りくじの存在を実証した今、この知識を以下のことに活用したいと考えている:
トレーニングのパフォーマンスを向上させる。当りくじは最初から単独でトレーニングできるため、当りくじを検索し、できるだけ早く枝刈りするトレーニングスキームを設計できることを期待している。
より優れたネットワークを設計する。当りくじは、学習に特に優れた疎なアーキテクチャと初期化の組み合わせを明らかにする。当りくじからインスピレーションを得て、学習に適した特性を持つ新しいアーキテクチャと初期化スキームを設計することができる。あるタスクで発見された当りくじを、他の多くのタスクに転用できる可能性もある。
ニューラル ネットワークの理論的理解を深める。ランダムに初期化されたフィードフォワード ネットワークに当りくじが含まれているように見える理由と、最適化 (Du 他、2019) と汎化 (Zhou 他、2018、Arora 他、2018) の理論的研究への潜在的な影響を研究できる。
このセクションでは、MNIST でトレーニングされた全結合ネットワークに適用された宝くじ仮説を評価する。図 2 で説明されているように、Lenet-300-100 アーキテクチャ (LeCun ら、1998) を使用する。セクション 1 の概要に従います。ネットワークをランダムに初期化してトレーニングした後、ネットワークを刈り込み、残りの接続を元の初期化にリセットする。単純なレイヤーごとの刈り込みヒューリスティックを使用する。各レイヤー内で最小の重みのパーセンテージを削除する (Han ら (2015) と同じ)。出力への接続は、ネットワークの残りの半分の速度で刈り込まれる。学習率、最適化戦略 (SGD、モメンタム)、初期化スキーム、ネットワーク サイズなど、その他のハイパーパラメータについては付録 G で説明する。
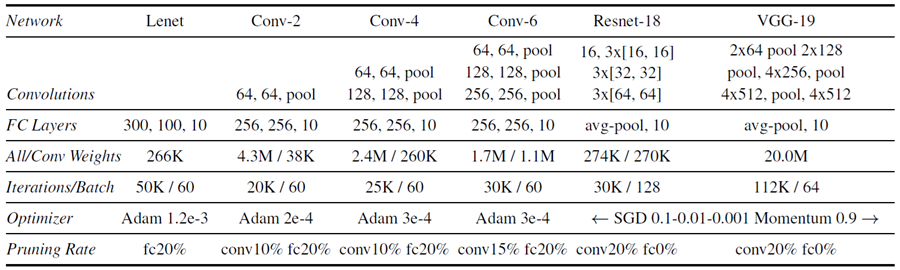
図 2: この論文でテストしたアーキテクチャ。畳み込みは 3x3 。Lenet は LeCun ら (1998) のもの。Conv-2/4/6 は VGG (Simonyan & Zisserman、2014) の変種。Resnet-18 は He ら (2016) のもの。CIFAR10 の VGG-19 は Liu ら (2019) から改変したもの。初期化は Gaussian Glorot (Glorot & Bengio、2010) 。括弧はレイヤーの周囲の残差接続を示す。
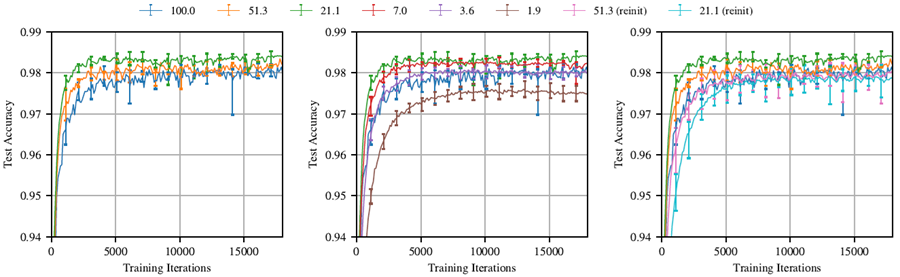
図3: 学習の進行に伴うLenet(反復枝刈り)におけるテスト精度の変化。各曲線は5回の試行の平均値。ラベルは\(P_m\)で、枝刈り後にネットワークに残る重みの割合。エラーバーは各試行における最小値と最大値を示す。
表記。\(P_m = \frac{||m||_0}{||\theta||}\) はマスク m のスパース性である。たとえば、重みの 75% が削減される場合、\(P_m\) = 25% になる。
反復枝刈り。我々が見つけた当りくじは、元のネットワークよりも速く学習する。図 3 は、さまざまな程度に反復的に枝刈りされた当りくじをトレーニングしたときの平均テスト精度をプロットしたものである。エラーバーは、5 回の実行の最小値と最大値である。最初の枝刈りラウンドでは、ネットワークは枝刈りされるほど速く学習し、テスト精度が高くなる (図 3 の左側のグラフ)。元のネットワークの重みの 51.3% を含む当りくじ (つまり、\(P_m\) = 51.3%) は、元のネットワークよりも速く高いテスト精度に達するが、\(P_m\) = 21.1% の場合よりも遅い。\(P_m\) < 21.1% の場合、学習が遅くなる (中央のグラフ)。\(P_m\) = 3.6% の場合、当りくじは元のネットワークのパフォーマンスに回帰する。同様のパターンが、本稿全体で繰り返される。
図4aは、反復ごとに20%ずつ枝刈りを行った場合(青)の、全ての枝刈りレベルにおける挙動をまとめたものである。左側は、各ネットワークが検証損失が最小値(つまり、早期停止基準によって学習が停止される時点)に達した反復回数と、枝刈り後に残る重みの割合の関係を示している。中央は、その反復回数におけるテスト精度である。早期停止基準が満たされた反復回数は、ネットワークの学習速度の指標として用いる。
\(P_m\) が 100% から 21% に減少するにつれて、当りくじの学習速度は速まり、この時点で早期停止は元のネットワークよりも 38% 早く発生する。さらに枝刈りを行うと学習速度が遅くなり、\(P_m\) = 3.6% のときに元のネットワークの早期停止パフォーマンスに戻る。枝刈りによってテスト精度が向上し、\(P_m\) = 13.5% のときに 0.3 パーセント ポイント以上向上する。この時点以降、精度は低下し、\(P_m\) = 3.6% のときに元のネットワークのレベルに戻る。
早期停止時には、訓練精度(図4a右)はテスト精度と同様のパターンで枝刈りによって向上しており、当りくじはより効果的に最適化されるものの、より汎化されていないことを示唆しているように見える。しかし、反復50,000回(図4b)では、ほぼすべてのネットワークで訓練精度が100%に達したにもかかわらず(付録D、図12)、反復枝刈りされた当りくじではテスト精度が最大0.35パーセントポイント向上している。これは、当りくじでは訓練精度とテスト精度の差が小さくなることを意味し、汎化が向上していることを示す。
ランダム再初期化。当りくじの初期化の重要性を測定するために、当りくじの構造(マスク m)はそのままに、新しい初期化 \(\theta'_0\sim\mathcal D_\theta\) をランダムにサンプリングする。各当りくじを3回ランダムに再初期化し、図4のポイントごとに合計15回再初期化する。初期化は当りくじの有効性にとって非常に重要であることがわかる。図3の右のグラフは、この反復枝刈り実験を示している。元のネットワークと当りくじ((P_m\) = 51% および 21%)に加えて、ランダム再初期化実験が示されている。当りくじは枝刈りされるにつれて学習速度が速くなるが、ランダムに再初期化されると学習速度は徐々に低下する。
この実験のより広範な結果は、図 4a のオレンジ色の線で示されている。当りくじとは異なり、再初期化されたネットワークは元のネットワークよりも学習速度が遅くなり、少しの枝刈り後にテスト精度が低下する。平均的な再初期化反復当りくじのテスト精度は、\(P_m\) = 21.1% のときに元の精度から低下するが、当りくじでは 2.9% である。\(P_m\) = 21% のとき、当りくじは再初期化時よりも 2.51 倍速く最小検証損失に達し、0.5 パーセントポイント精度が向上する。すべてのネットワークは、\(P_m\geq\)5% で 100% のトレーニング精度に達する。したがって、図 4b は、当りくじがランダムに再初期化された場合よりも大幅に汎化されることを示している。この実験は、宝くじ仮説における初期化の重要性を裏付けている。元の初期化は枝刈りに耐え、その恩恵を受けるが、ランダムに再初期化された当りくじのパフォーマンスはすぐに低下し、着実に低下していく。
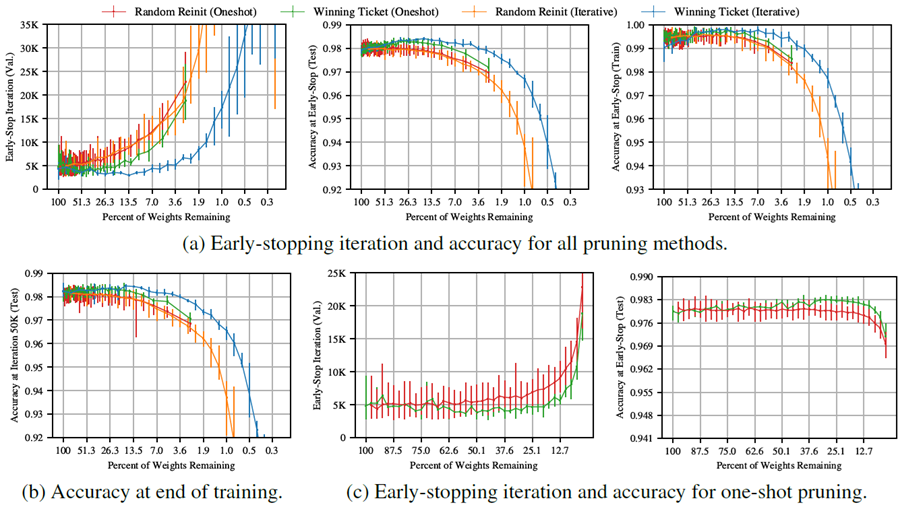
図4: ワンショットおよび反復枝刈りにおけるLenetの早期停止反復と精度。5回の試行の平均値。最小値と最大値のエラーバー。反復50,000回では、反復的勝利チケットの訓練精度は\(P_m\\geq) 2%で\(y\approx\)100%となった(付録D、図12参照)。
ワンショット・プルーニング。反復プルーニングはより小さな当りくじを抽出するが、反復トレーニングはそれらを見つけるのにコストがかかることを意味する。ワンショット・プルーニングは、この反復トレーニングなしで当りくじを識別することを可能にする。図4cは、ワンショット・プルーニング(緑)とランダム再初期化(赤)の結果を示している。ワンショット・プルーニングは確かに当りくじを見つける。67.5%\(\geq P_m\geq\)17.6%の場合、平均的な当りくじは元のネットワークよりも早く最小検証精度に達する。95.0%\(\geq P_m\geq\) 5.17%の場合、テスト精度は元のネットワークよりも高くなる。しかし、反復プルーニングされた当りくじはより速く学習し、より小さなネットワークサイズでより高いテスト精度に達する。図4cの緑と赤の線は図4aの対数軸上に再現されており、このパフォーマンスの差を明確に示している。我々の目標は、可能な限り最小の当りくじを特定することなので、論文の残りの部分では反復的な枝刈りに焦点を当てる。
ここでは、宝くじ仮説を CIFAR10 の畳み込みネットワークに適用し、学習問題の複雑さとネットワークのサイズの両方を増加さる。図2 の Conv-2、Conv-4、および Conv-6 アーキテクチャを検討する。これらは、VGG (Simonyan & Zisserman、2014) ファミリーの縮小版である。ネットワークには、2、4、または 6 つの畳み込み層があり、その後に 2 つの全結合層が続く。最大プーリングは、2 つの畳み込み層ごとに入る。ネットワークは、ほぼ全結合から従来の畳み込みネットワークまでの範囲をカバーし、Conv-2 では畳み込み層のパラメータが 1% 未満であるが、Conv-6 ではほぼ 3 分の 2 になる。3
3 付録 H では、学習率、最適化戦略 (SGD、モメンタム)、畳み込み層と全結合層を削減する相対率など、その他のハイパーパラメータについて説明する。
当りくじの発見。図5(上)の実線は、図2の層ごとの枝刈り率で、Conv-2(青)、Conv-4(オレンジ)、Conv-6(緑)の反復宝くじ実験を示している。セクション2のLenetのパターンが繰り返される。つまり、ネットワークが枝刈りされるにつれて、元のネットワークと比較して学習速度が上がり、テスト精度が向上する。この場合、結果はより顕著である。当りくじは、Conv-2で最大3.5倍(\(P_m\) = 8.8%)、Conv-4で3.5倍(\(P_m\) = 9.2%)、Conv-6で2.5倍(\(P_m\) = 15.1%)速く、最小検証損失に達する。テスト精度は、Conv-2(\(P_m\) = 4.6%)で最大3.4パーセントポイント、Conv-4(\(P_m\) = 11.1%)で最大3.5パーセントポイント、Conv-6(\(P_m\) = 26.4%)で最大3.3パーセントポイント向上する。3つのネットワークはすべて、\(P_m\) > 2%の場合でも、元の平均テスト精度を上回っている。
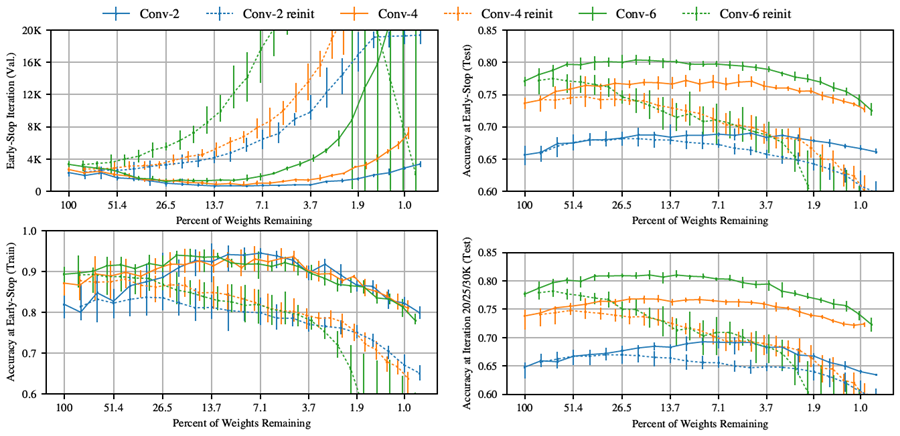
図5: 反復枝刈りおよびランダム再初期化を行ったConv-2/4/6アーキテクチャの早期停止反復とテストおよびトレーニング精度。実線は5回の試行の平均、破線は15回の再初期化(試行ごとに3回)の平均。右下のグラフは、元のネットワークのトレーニングの最終反復(Conv-2の場合は20,000回、Conv-4の場合は25,000回、Conv-6の場合は30,000回)に対応する反復における当りくじのテスト精度を示している。この反復では、勝ちチケットのトレーニング精度は\(約\) 100%、\(P_m\\gt\) 2%だった(付録Dを参照)。
セクション2と同様に、早期停止反復における学習精度はテスト精度とともに向上する。しかし、Conv-2では20,000回、Conv-4では25,000回、Conv-6では30,000回(元のネットワークの最終学習反復に相当する反復)において、\(P_m\geq\) 2%のときにすべてのネットワークで学習精度が100%に達する(付録D、図13)。また、当りくじは依然として高いテスト精度を維持している(図5右下)。これは、当りくじではテスト精度と学習精度の差が小さく、より汎化が進んでいることを示している。
ランダム再初期化。セクション2で行ったランダム再初期化実験を繰り返す。これは図5の破線で示されている。これらのネットワークは、枝刈りを続けると学習時間が長くなる。MNISTにおけるLenet(セクション2)と同様に、ランダム再初期化実験ではテスト精度がより急速に低下する。しかし、Lenetとは異なり、早期停止時のテスト精度は当初は安定しており、Conv-2とConv-4ではさらに向上している。これは、中程度の枝刈りでは、当りくじの構造のみで精度が向上する可能性があることを示している。
ドロップアウト。ドロップアウト(Srivastava et al., 2014; Hinton et al., 2012)は、各学習反復においてユニットの一部をランダムに無効化(すなわち、サブネットワークをランダムにサンプリング)することで精度を向上させる。Baldi & Sadowski (2013) は、ドロップアウトを全てのサブネットワークのアンサンブルを同時に学習させるものと特徴付けている。宝くじ仮説は、これらのサブネットワークの1つが当りくじを構成することを示唆しているため、ドロップアウトと当りくじを見つけるための我々の戦略が相互作用するかどうかという疑問が生じるのは当然である。
図 6 は、ドロップアウト率 0.5 で Conv-2、Conv-4、Conv-6 をトレーニングした結果を示している。破線はドロップアウトなしのネットワーク パフォーマンスである (図 5 の実線)。4 ドロップアウトありでトレーニングした場合でも、当りくじを見つけ続けている。ドロップアウトにより初期テスト精度が向上し (Conv-2、Conv-4、Conv-6 でそれぞれ平均 2.1、3.0、2.4 パーセント ポイント)、反復プルーニングにより精度がさらに向上する (それぞれ平均で最大 2.3、4.6、4.7 パーセント ポイント向上)。反復プルーニングにより学習は以前と同様に高速化されるが、Conv-2 の場合はそれほど劇的ではない。
4 ドロップアウトを使用してトレーニングしたネットワークの新しい学習率を選択する(付録H.5を参照)。
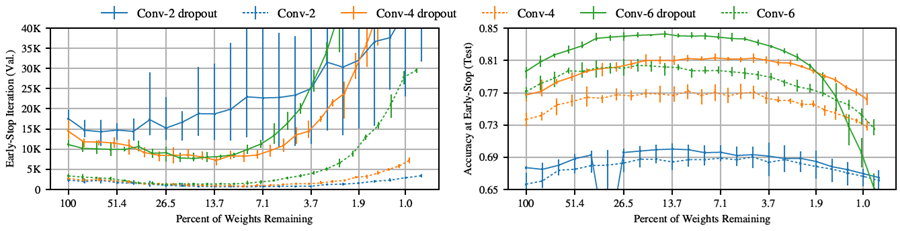
図6: 反復的に枝刈りし、ドロップアウトを用いて学習させたConv-2/4/6の早期停止反復回数と早期停止時のテスト精度。破線は、ドロップアウトなしで学習させたネットワーク(図5の実線)と同じネットワーク。学習率は、Conv-2では0.0003、Conv-4とConv-6では0.0002。
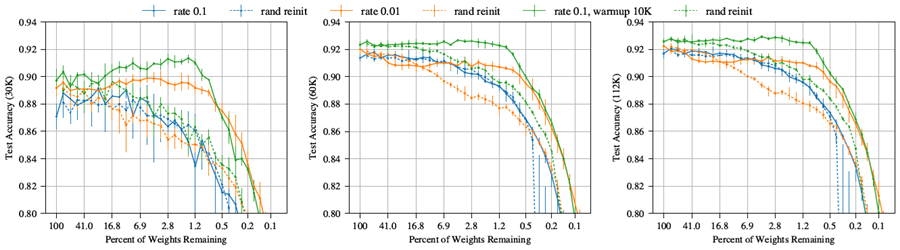
図 7: 反復的に枝刈りした場合の VGG-19 のテスト精度 (30K、60K、112K 反復時)。
これらの改善は、我々の反復的な枝刈り戦略がドロップアウトと相補的に相互作用することを示唆している。Srivastavaら (2014) は、ドロップアウトが最終的なネットワークにおいてスパースな活性化を誘発することを観察している。ドロップアウトによって誘発されたスパース性が、ネットワークを枝刈りの対象に仕立てている可能性がある。もしそうであれば、重みをターゲットとするドロップアウト手法 (Wanら, 2013) や、重みごとのドロップアウト確率を学習するドロップアウト手法 (Molchanovら, 2017; Louizosら, 2018) によって、当りくじの発見がさらに容易になる可能性がある。
本稿では、実際に使用されているアーキテクチャと手法を想起させるネットワークにおいて、宝くじ仮説を検証する。具体的には、VGGスタイルの深層畳み込みネットワーク(CIFAR10のVGG-19—Simonyan & Zisserman (2014))と残差ネットワーク(CIFAR10のResnet-18—He et al. (2016))を検討する。5 これらのネットワークは、バッチ正規分布、重み減衰、学習率減少スケジュール、および学習データ拡張を用いて学習される。我々はこれらすべてのアーキテクチャにおいて、当りくじを見つけ続けているが、それらを見つけるための手法である反復的枝刈りは、使用される特定の学習率に敏感である。これらの実験では、早期停止時間(これらの大規模ネットワークでは学習率スケジュールと絡み合っている)を測定するのではなく、学習中のいくつかの時点で精度をプロットし、精度が向上する相対的な速度を示す。
5 ネットワーク、ハイパーパラメータ、トレーニング方法の詳細については、図2と付録Iを参照。
グローバルプルーニング。Lenet および Conv-2/4/6 では、各層を個別に同じレートで枝刈りする。Resnet-18 および VGG-19 では、この戦略を少し変更する。つまり、これらの深いネットワークをグローバルプルーニングし、すべての畳み込み層にわたって最小の大きさの重みをまとめて削除する。付録 I.1 では、グローバルプルーニングによって Resnet-18 および VGG-19 でより小さな当りくじが特定されることがわかった。この動作に対する推測の説明は次のとおりである。これらの深いネットワークでは、一部の層は他の層よりもはるかに多くのパラメーターを持っている。たとえば、VGG-19 の最初の 2 つの畳み込み層には 1728 と 36864 のパラメーターがあるが、最後の層には 235 万のパラメーターがある。すべての層が同じレートでプルーニングされると、これらの小さな層がボトルネックになり、可能な限り小さい当りくじを特定できなくなる。グローバルプルーニングにより、この落とし穴を回避できる。
VGG-19。Liuら(2019)がCIFAR10向けに改良した変種 VGG-19を研究対象とする。学習方法とハイパーパラメータは、160エポック(112,480回の反復)、SGD(モメンタム値0.9)を使用し、80エポックと120エポックで学習率を10分の1に減少させた。このネットワークのパラメータ数は2,000万個である。図7は、VGG-19に対して、初期学習率0.1(Liuら(2019)で使用)と0.01の2種類で反復的枝刈りとランダム再初期化を行った結果を示している。より高い学習率では、反復的枝刈りでは当りくじが見つからず、枝刈りされたネットワークをランダムに再初期化した場合と比べてパフォーマンスは向上しなかった。しかし、学習率が低い場合、通常のパターンが再び現れ、サブネットワークは元の精度の1パーセントポイント以内に留まり、\(P_m\geq\) 3.5% に達する。(元の精度と一致しないため、これらは当りくじではない。)ランダムに再初期化すると、本論文の他の実験と同様に、サブネットワークは枝刈りされるため、精度が低下する。これらのサブネットワークは、トレーニング初期段階では枝刈りされていないネットワークよりも高速に学習するが(図7左)、初期学習率が低いため、この精度の優位性はトレーニング後期には薄れていく。しかし、これらのサブネットワークは、再初期化した場合よりも依然として高速に学習する。
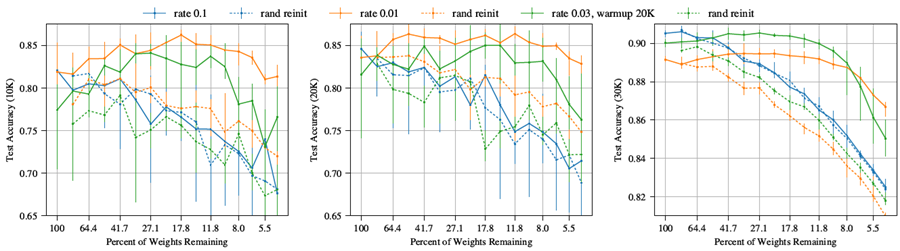
図 8: 反復的にプルーニングした場合の Resnet-18 のテスト精度 (10K、20K、30K 反復時)。
低い学習率における当りくじのような挙動と、高い学習率における精度の優位性との間のギャップを埋めるため、k回の反復処理において、学習率0から初期学習率までの線形ウォームアップの効果を調査する。学習率0.1でウォームアップ(k = 10000、緑線)を用いてVGG-19をトレーニングすると、枝刈りなしネットワークのテスト精度が約1パーセントポイント向上する。ウォームアップにより当りくじを見つけることが可能になり、\(P_m\geq\) 1.5%のときに初期精度を上回る。
Resnet-18。Resnet-18 (He et al., 2016) は、CIFAR10 向けに設計された残差接続を持つ 20 層の畳み込みネットワークである。パラメータ数は 271,000 である。このネットワークを、モーメンタム (0.9) を用いた SGD で 30,000 回の反復学習を行った。20,000 回目と 25,000 回目の反復では学習率を 1/10 に下げた。図 8 は、学習率 0.1 (He et al. (2016) で使用) と 0.01 での反復枝刈りとランダム再初期化の結果を示している。これらの結果は VGG の結果とほぼ一致している。反復枝刈りは、低い学習率では当りくじを見つけるが、高い学習率では見つけない。最も優れた当りくじの精度は、低い学習率 (41.7% \(\geq P_m\geq\) 21.9% の場合に 89.5%) であるが、高い学習率での元のネットワークの精度 (90.5%) を下回っている。 低い学習率では、当たりチケットは最初のうちは学習が速くなるが (図 8 の左のプロット)、トレーニングの後半では高い学習率の枝刈りされていないネットワークに遅れをとる (右のプロット)。 ウォームアップを使用してトレーニングされた当りくじは、高い学習率で枝刈りされていないネットワークとの精度のギャップを埋め、学習率 0.03 (ウォームアップ、\(k\) = 20000)、\(P_m\) = 27.1% で 90.5% のテスト精度に達する。 これらのハイパーパラメータでは、\(P_m\geq\) 11.8% の場合でも当りくじを見つけることができる。しかし、ウォームアップを行っても、元の学習率 0.1 で当りくじを識別できるハイパーパラメータを見つけることができなかった。
ニューラルネットワークの枝刈りに関する既存の研究(例:Han et al. (2015))は、ニューラルネットワークによって学習された関数は、多くの場合、より少ないパラメータで表現できることを実証している。枝刈りは通常、元のネットワークを学習し、接続を削除し、さらに微調整することで進められる。実際には、初期学習では枝刈りされたネットワークの重みが初期化され、微調整中に独立して学習できるようになる。我々は、同様に疎なネットワークが最初から学習できるかどうかを明らかにしようとしている。本論文で検討したアーキテクチャには、そのような学習可能なサブネットワークが確実に含まれており、宝くじ仮説はこの特性が一般に当てはまることを示唆している。当りくじの存在と性質に関する我々の経験的研究は、多くの追加の疑問を喚起する。
当りくじの初期化の重要性。ランダムに再初期化されると、当りくじの学習速度が遅くなり、テスト精度も低下する。これは、初期化が成功に重要であることを示唆している。この動作の1つの説明として、これらの初期重みはトレーニング後の最終値に近い、つまり極端な場合には既にトレーニング済みであるということが考えられる。しかし、付録Fの実験では、その逆の結果が示されている。つまり、当りくじの重みは他の重みよりも大きく変化する。これは、初期化の利点が最適化アルゴリズム、データセット、およびモデルに関連していることを示唆している。例えば、当りくじの初期化は、選択された最適化アルゴリズムによって特に最適化しやすい損失ランドスケープの領域に収まる可能性がある。
Liu ら (2019) は、ランダムに再初期化すると、枝刈りされたネットワークは実際にトレーニング可能であることを発見した。これは一見、従来の知見や我々のランダム再初期化実験と矛盾している。たとえば、VGG-19 (同じセットアップを共有) では、ネットワークを最大 80% 枝刈りし、ランダムに再初期化すると、元のネットワークの精度と一致することがわかった。図 7 の実験は、このレベルのスパース性 (Liu らはこれより低いレベルではデータを提示していない) でこれらの発見を確認した。ただし、さらに枝刈りを行うと、初期化が重要になる。VGG-19 を最大 98.5% 枝刈りすると当りくじが見つかる。再初期化すると、これらのチケットの精度は大幅に低下する。我々は、一定のレベルのスパース性まで、過度にオーバーパラメータ化されたネットワークを枝刈り、再初期化、再トレーニングすることで成功できると仮定している。ただし、この点を超えると、極端に枝刈りされ、それほど過剰パラメータ化されていないネットワークは、偶然の初期化によってのみ精度を維持する。
当りくじ構造の重要性。当りくじを生み出す初期化は、特定のスパースアーキテクチャで構成されている。我々は訓練データを多用することで当りくじを発見するため、当りくじの構造は、学習タスクに合わせてカスタマイズされた帰納バイアスをエンコードしているという仮説を立てている。Cohen & Shashua (2016) は、深層ネットワークの構造に埋め込まれた帰納バイアスが、浅層ネットワークよりもパラメータ効率の高いデータ分離を可能にすることを示している。Cohen & Shashua (2016) は畳み込みネットワークのプーリング形状に焦点を当てているが、当りくじの構造にも同様の効果が働き、大幅に枝刈りされた状態でも学習が可能になる可能性がある。
当りくじの汎化の向上。より汎化が進み、元のネットワークのテスト精度を超えながらも、その訓練精度と同等の当りくじを確実に見つけることができる。枝刈りを行うとテスト精度は増加し、その後減少する。オッカムの丘(Rasmussen & Ghahramani, 2001)は、元の過剰パラメータ化されたモデルは複雑性が高すぎる(おそらく過適合)のに対し、極端に枝刈りされたモデルは複雑性が低すぎるという状況である。圧縮と汎化の関係に関する従来の見解は、コンパクトな仮説の方が汎化しやすいというものである(Rissanen, 1986)。最近の理論的研究はニューラルネットワークにおいても同様の関連性を示しており、さらに圧縮可能なネットワークでは汎化の境界がより狭くなることを証明している(枝刈り/量子化についてはZhou et al. (2018)、ノイズ耐性についてはArora et al. (2018))。宝くじ仮説は、この関係について補完的な視点、すなわち大規模なネットワークにはより単純な表現が明示的に含まれる可能性があるという視点を提供している。
ニューラルネットワーク最適化への影響。当りくじは、元の枝刈りされていないネットワークと同等の精度を、大幅に少ないパラメータで達成できる。この観察結果は、ニューラルネットワークのトレーニングにおける過剰パラメータ化の役割に関する最近の研究と関連している。例えば、Duら (2019) は、SGDでトレーニングされた十分に過剰パラメータ化された2層Reluネットワーク(固定サイズの第2層)が、グローバル最適解に収束することを証明している。そこで重要な疑問は、SGDがニューラルネットワークを特定のテスト精度に最適化するために、当りくじの存在が必要または十分であるかどうかである。我々は、SGDが適切に初期化されたサブネットワークを探し出してトレーニングすると推測するが(経験的には示していない)、この論理によれば、過剰パラメータ化されたネットワークは、潜在的な当りくじとなるサブネットワークの組み合わせが多いため、トレーニングが容易になる。
本研究では、小規模データセット(MNIST、CIFAR10)における視覚中心の分類タスクのみを対象としている。大規模データセット(Imagenet(Russakovsky et al., 2015)など)は調査していない。反復枝刈りは計算量が多く、ネットワークを複数回の試行で15回以上連続して学習させる必要があるためである。今後の研究では、より効率的な当りくじ発見手法を探求し、よりリソース集約的な環境において宝くじ仮説を研究できるようにしたいと考えている。
スパースプルーニングは、当りくじを見つけるための唯一の手法である。パラメータ数を削減できるものの、結果として得られるアーキテクチャは最新のライブラリやハードウェアに最適化されていない。今後の研究では、構造化プルーニング(最新のハードウェアに最適化されたネットワークを生成)や非マグニチュードプルーニング(より小さな当りくじを生成したり、より早く発見したりできる)など、豊富な最新文献から他のプルーニング手法を研究する予定である。
我々が発見した当りくじは、ランダムに初期化されたネットワークでは実現できないほど小さいサイズにおいて、枝刈りなしネットワークのパフォーマンスに匹敵する初期化値を持っている。今後の研究では、これらの初期化値の特性、つまり枝刈り済みネットワークアーキテクチャの帰納バイアスと相まって、これらのネットワークが特に学習に優れている理由を研究する予定である。
より深いネットワーク(Resnet-18およびVGG-19)では、学習率ウォームアップを用いてネットワークを学習しない限り、反復枝刈りでは当りくじを見つけることができない。今後の研究では、ウォームアップが必要な理由と、当りくじを特定するための手法に他の改善を加えることで、これらのハイパーパラメータの変更が不要になるかどうかを調査する予定である。
実際には、ニューラルネットワークは大幅に過剰パラメータ化される傾向がある。蒸留(Ba & Caruana, 2014; Hinton et al., 2015)と枝刈り(LeCun et al., 1990; Han et al., 2015)は、精度を維持しながらパラメータを削減できるという事実に基づいている。学習データを記憶するのに十分な容量があっても、ネットワークは自然に単純な関数を学習する(Zhang et al., 2016; Neyshabur et al., 2014; Arpit et al., 2017)。近年の経験(Bengio et al., 2006; Hinton et al., 2015; Zhang et al., 2016)と図1は、過剰パラメータ化されたネットワークの方が学習が容易であることを示唆している。密なネットワークには、元の初期化から開始して自己学習可能な疎なサブネットワークが含まれていることを示す。他のいくつかの研究方向は、小規模または疎なネットワークのトレーニングを目的としている。
トレーニング前:Squeezenet(Iandola et al., 2016)とMobileNets(Howard et al., 2017)は、標準的なアーキテクチャよりも桁違いに小さい、特別に設計された画像認識ネットワークである。Denil ら(2013) は、重み行列を低ランク因子の積として表す。Li et al. (2018) は、最適化をパラメータ空間の小さなランダムサンプリングされた部分空間に制限し(つまり、すべてのパラメータを更新可能)、この制限下でネットワークの学習に成功した。本研究では、ネットワークを最適化するためにすべてのパラメータを更新する必要はなく、枝刈りを含む原理的な探索プロセスを通じて、最適なネットワークを見つけ出すことができることを示す。このクラスのアプローチへの貢献は、大規模ネットワーク内にスパースで学習可能なネットワークが存在することを実証することである。
トレーニング後。蒸留 (Ba & Caruana, 2014; Hinton et al., 2015) は、小規模ネットワークをトレーニングして大規模ネットワークの挙動を模倣する。小規模ネットワークのトレーニングはこのパラダイムの方が容易である。最近の枝刈りの研究では、大規模モデルを圧縮して限られたリソース (モバイル デバイスなど) で実行できるようにしている。枝刈りは我々の実験の中心であるが、我々は、なぜトレーニングに、枝刈りを可能にする過剰パラメータ化されたネットワークが必要なのかを調査する。LeCun et al. (1990) と Hassibi & Stork (1993) は、2 次導関数に基づく枝刈りを初めて検討した。最近では、Han et al. (2015) は、重みごとの大きさに基づく枝刈りによって画像認識ネットワークのサイズが大幅に削減されることを示した。Guo et al. (2016) は、枝刈りされた接続が再び関連性を持つようになったときに、それを復元する。Han et al. (2017) と Jin et al. (2016) は、小さな重みが刈り込まれ、生き残った重みが微調整された後に、ネットワーク容量を増やすために刈り込まれた接続を復元する。他の提案されている刈り込みヒューリスティックとしては、活性化 (Hu et al., 2016)、冗長性 (Mariet & Sra, 2016; Srinivas & Babu, 2015a)、層ごとの二次導関数 (Dong et al., 2017)、エネルギー/計算効率 (Yang et al., 2017) に基づく刈り込みがある (例: 畳み込みフィルター (Li et al., 2016; Molchanov et al., 2016; Luo et al., 2017) またはチャネル (He et al., 2017) の刈り込み)。Cohen et al. (2016) は、畳み込みフィルターが初期化の影響を受けやすいことを指摘している (「フィルターくじ」)。トレーニング全体を通して、重要でないフィルターをランダムに再初期化する。
トレーニング中。Bellec et al. (2018) はスパースネットワークを用いて訓練を行い、ゼロに達した重みを新しいランダム接続に置き換えた。Srinivas ら (2017) とLouizos ら (2018) は、非ゼロパラメータの数を最小化するゲーティング変数を学習した。Narang ら (2017) は、マグニチュードベースのプルーニングを訓練に統合した。Gal & Ghahramani (2016) は、ドロップアウトがガウス過程におけるベイズ推論を近似することを示している。ベイズ的な観点から見ると、ドロップアウトは訓練中にドロップアウト確率を学習する (Gal et al., 2017; Kingma et al., 2015; Srinivas & Babu, 2016)。重みごと、ユニットごと(Srinivas & Babu, 2016)、あるいは構造化されたドロップアウト確率を自然に(Molchanov et al., 2017; Neklyudov et al., 2017)、あるいは明示的に(Louizos et al., 2017; Srinivas & Babu, 2015b)学習する手法は、一部の重みのドロップアウト確率が1に達すると、学習中にネットワークを刈り込み、スパース化する。一方、我々は当りくじを見つけるためにネットワークを少なくとも1回学習する。これらの手法も当りくじを見つける可能性があり、あるいはスパース化を誘導することで、我々の手法と有益な相互作用をする可能性がある。
本論文の実験に必要な計算リソースをMIT-IBM Watson AI Labを通じて提供いただいたIBMに深く感謝いたします。特に、IBMの研究員であるGerman Goldszmidt氏、David Cox氏、Ian Molloy氏、Benjamin Edwards氏には、インフラ、技術サポート、そしてフィードバックという惜しみない貢献をいただき、深く感謝申し上げます。また、本プロジェクトを通してサポート、フィードバック、そして有益な議論をしてくださったAleksander Madry氏、Shafi Goldwasser氏、Ed Felten氏、David Bieber氏、Karolina Dziugaite氏、Daniel Weitzner氏、R. David Edelman氏にも感謝申し上げます。本研究は、米国海軍研究局(ONR N00014-17-1-2699)の支援を受けて実施されました。
この付録では、論文本体全体で当りくじを見つけるために使用する反復的な枝刈り戦略を構築する 2 つの異なる方法を検討する。
戦略 1: リセットを伴う反復枝刈り
これら2つの戦略の違いは、各ラウンドの枝刈りの後、戦略2では既に学習済みの重みを用いて再学習を行うのに対し、戦略1ではネットワークの重みを再学習前に初期値にリセットすることである。どちらの場合も、ネットワークが十分に枝刈りされた後、重みは元の初期化値にリセットされる。
図 9 と 10 は、付録 G と H で選択したハイパーパラメータに基づいて、Lenet と Conv-2/4/6 アーキテクチャの 2 つの戦略を比較したものである。いずれの場合も、戦略 1 は、ネットワーク サイズが小さくても、より高い検証精度とより速い早期停止時間を維持している。
本論文全体を通して、ネットワークの学習速度の測定に着目している。この量の代理として、早期停止基準が学習を終了する反復回数を測定する。ここで用いる具体的な基準は、検証損失が最小となる反復回数である。このサブセクションでは、この基準についてさらに詳しく説明する。
検証損失とテスト損失は、学習プロセスの初期段階で減少し、最小値に達した後、モデルが学習データに過剰適合するにつれて増加し始めるというパターンを示しる。図11は、学習の進行に伴う検証損失の例を示している。これらのグラフでは、Lenet法、反復的プルーニング、および学習率0.0012(次のサブセクションで選択する学習率)のAdamを使用している。この図は、図3のテスト精度に対応する検証損失を示している。
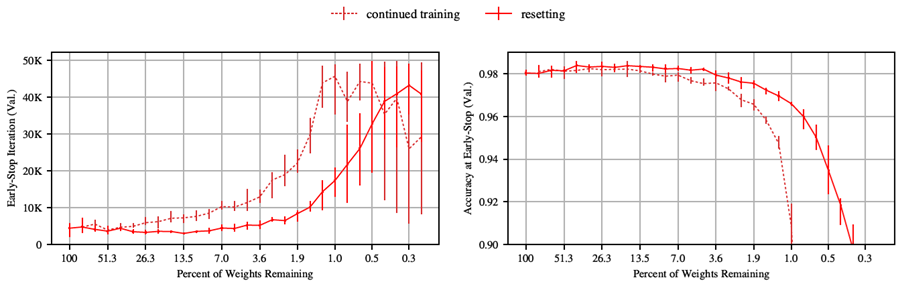
図 9: リセットおよび継続トレーニング戦略を使用して反復的に枝刈りした場合の、Lenet アーキテクチャ上の反復宝くじ実験の早期停止反復と早期停止時の精度。
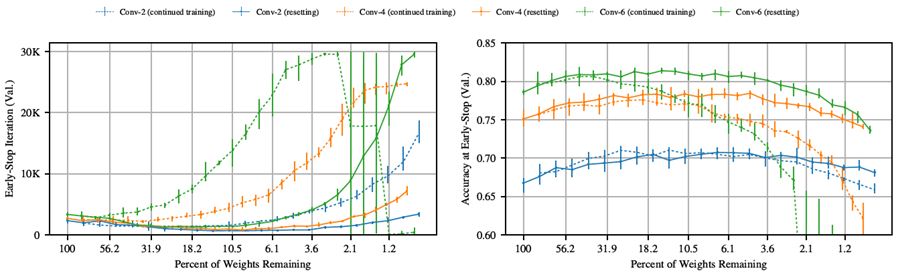
図 10: リセットおよび継続トレーニング戦略を使用して反復的に枝刈りした場合の、Conv-2、Conv-4、および Conv-6 アーキテクチャでの反復宝くじ実験の早期停止反復と早期停止時の精度。
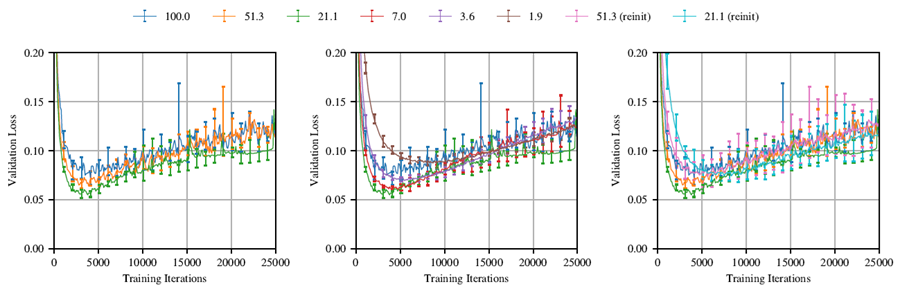
図11:図3に対応する検証損失データ。反復的枝刈り実験において、複数の異なるレベルの枝刈りにおけるトレーニングの進行に伴う検証損失。各線は、同じ反復的枝刈りレベルでの5回のトレーニング実行の平均である。ラベルは、枝刈り後に残る元のネットワークの重みのパーセンテージである。各ネットワークは、学習率0.0012でAdamを使用してトレーニングされた。左のグラフは、元のネットワークよりも学習速度が上がり、損失が低減する当りくじを示している。中央のグラフは、最速の早期停止時間に達した後、学習速度が下がり続ける当りくじを示している。右のグラフは、当りくじの損失とランダムに再初期化されたネットワークの損失を対比している。
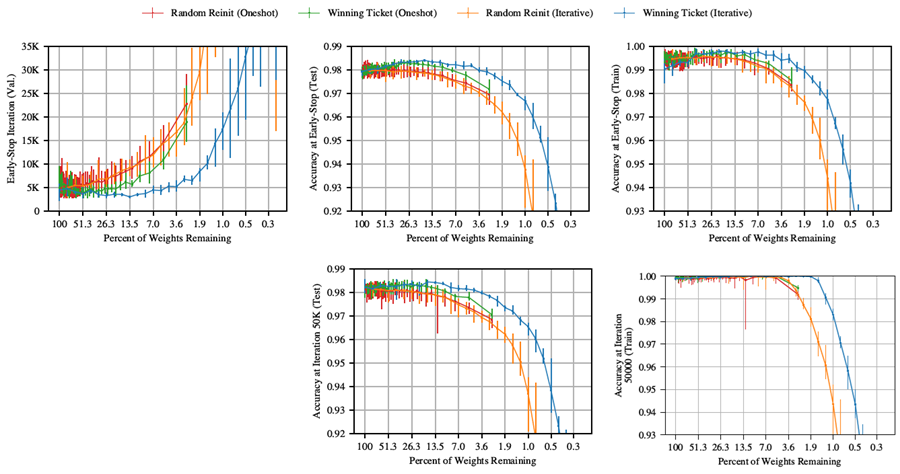
図 12: 図 4 に、50,000 回の反復終了時のトレーニング精度のグラフを追加した。
いずれの場合も、検証損失は最初は減少し、その後明確な底を形成し、その後再び増加し始める。この底を特定するのが、我々の早期停止基準である。この瞬間に早く到達したネットワークは、「より速く」学習したとみなす。この考えを裏付けるように、図3において各実験が早期停止基準を満たす順序は、図3において各実験が特定のテスト精度閾値に到達する順序と同じである。
本論文では、この学習速度を文脈に沿って説明するため、検証損失が最小となる反復におけるネットワークのテスト精度も示す。本文では、当りくじは早期停止に早く到達し、この時点で高いテスト精度に達することを示している。
この付録は、論文本体の図 4 (セクション 2 の MNIST に対する Lenet の精度と早期停止の反復) と図 5 (セクション 3 の Conv-2、Conv-4、Conv-6 の精度と早期停止の反復) に付随するものである。 これらの図は、早期停止の反復、早期停止時のテスト精度、早期停止時のトレーニング精度、およびトレーニングプロセス終了時のテスト精度を示している。 ただし、トレーニングプロセス終了時のトレーニング精度のグラフを含めるスペースがなかった。論文本体では、最も厳しく枝刈りされたネットワークを除くすべてのネットワークでトレーニング精度が 100% であると主張している。 この付録では、図 12 (図 4 に対応) と図 13 (図 5 に対応) にそれらの追加グラフを含める。論文本文で述べたように、最も厳しく枝刈りされたネットワークを除くすべてのケースにおいて、訓練精度は100%に達する。ただし、ランダムに再初期化されたネットワークと比較して、当りくじの訓練精度が100%を維持する時間は長くなる。
この付録では、ランダムに再初期化された当りくじとランダムにスパースなネットワークの相対的なパフォーマンスを理解することを目指す。
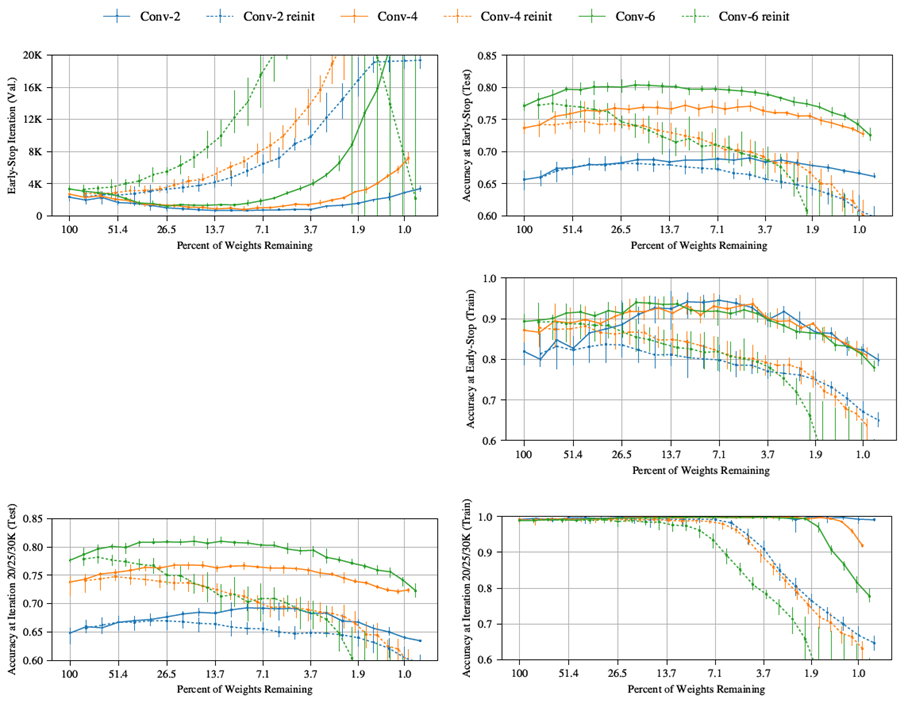
図 13: トレーニング プロセス終了時のトレーニング精度のグラフを追加した図 5。
図14は、本論文の主要な実験すべてについて、この比較を示している。MNISTの全結合Lenetアーキテクチャでは、ランダム再初期化ネットワークがランダムスパースネットワークよりも優れた性能を示すことがわかった。しかし、本論文で検討した他のすべての畳み込みネットワークでは、両者の性能に大きな差は見られなたっか。MNISTの全結合ネットワークがこれらの利点を享受できるのは、MNIST画像の特定の部分にのみ分類に有用な情報が含まれているため、ネットワークの一部の接続が他の部分よりも価値が高いためだと考えられる。これは、入力画像の特定の部分に制約されない畳み込みの場合にはあまり当てはまらない。
この付録では、当りくじの構造を検証し、当りくじがなぜこれほどまでに枝刈りされた状態でも効果的に学習できるのかを考察する。この付録では、MNISTで学習されたLenetアーキテクチャの当りくじを考察する。特に断りのない限り、セクション2と同じハイパーパラメータ(glorot初期化とadam最適化)を使用する。
図15は、4つの異なるレベルの\(P_m\)における当りくじの初期化の分布を示している。明確にするために、これらは枝刈り処理を生き残った接続の初期重みの分布である。青、オレンジ、緑の線は、それぞれ第1隠れ層、第2隠れ層、出力層の重みの分布を示している。重みは宝くじ実験の5つの異なる試行から収集されているが、各試行の分布は、すべての試行から集計された分布とほぼ一致している。ヒストグラムは、各曲線の下の面積が1になるように正規化されている。
図15の左端のグラフは、枝刈り前のネットワークの初期化分布を示している。glorot初期化を使用しているため、各層の標準偏差は異なる。ネットワークが枝刈りされるにつれて、第1隠れ層はその分布を維持する。しかし、第2隠れ層と出力層は次第に二峰性となり、0の両側にピークが現れる。興味深いことに、ピークは非対称である。第2隠れ層には正の初期化が負の初期化よりも多く残っており、出力層ではその逆となっている。
枝刈り処理を生き残った第2隠れ層と出力層の接続は、より大きな重みを持つ初期化を持つ傾向がある。各層で最小の重みを持つ接続を最後に枝刈りすることで当りくじを見つけるため、最小の重みを持つ初期化を持つ接続は、訓練終了時にも重みが最小のままである必要がある。入力層では異なる傾向が見られる。つまり、入力層はその分布を維持するため、接続の初期化と最終的な重みの関係は小さくなる。
また、ネットワークを SGD 学習率 0.8 (付録 G の説明に従って選択) でトレーニングしたときに取得された当りくじも検討する。図 15 の双峰分布は、すべてのレイヤーにわたって存在する (図 16 を参照)。最も大きな初期化を持つ接続は、枝刈りプロセスを生き残る可能性が高くなる。つまり、当りくじの初期化は、0 の反対側にピークを持つ双峰分布になる。adam 最適化された当りくじと同様に、これらのピークはサイズが異なり、最初の非表示層は負の初期化を優先し、2 番目の非表示層と出力層は正の初期化を優先する。adam の結果と同様に、個々の試行ごとに、図 16 の集約グラフと同じ非対称性が示されることが確認された。
当りくじの初期化分布 \(\mathcal D_m\) が、枝刈り前ネットワークの初期化に使用されたガウス分布 \(\mathcal D\) と大きく異なることを考慮すると、当りくじを \(\mathcal D\) ではなく \(\mathcal D_m\) からランダムに再初期化すると、当りくじのパフォーマンスが向上するかどうかを尋ねるのは当然である。これは当てはまらない。図 17 は、ADAMの当りくじに含まれる初期化の分布からランダムにサンプリングされた初期化を持つ当りくじのパフォーマンスを示している。より具体的には、マスク \(m\) を持つ当りくじで見つかった初期化の集合を \(\mathcal D_m = \{\theta_0^{(i)}\mid m^{(i)}=1\}\) とする。新しいパラメータセット \(\theta'_0\sim\mathcal D_m\) をサンプリングし、ネットワーク \(f(x;m\odot\theta'_0)\) を学習させる。このサンプリングはレイヤーごとに行う。この実験の結果は図17に示されている。\(\mathcal D_m\) から再初期化された当りくじは、\(\mathcal D\) からランダムに再初期化された場合と比べて、わずかにパフォーマンスが向上した。SGD 学習済みの当たりチケットでも同じ実験を試みたところ、同様の結果が得られた。
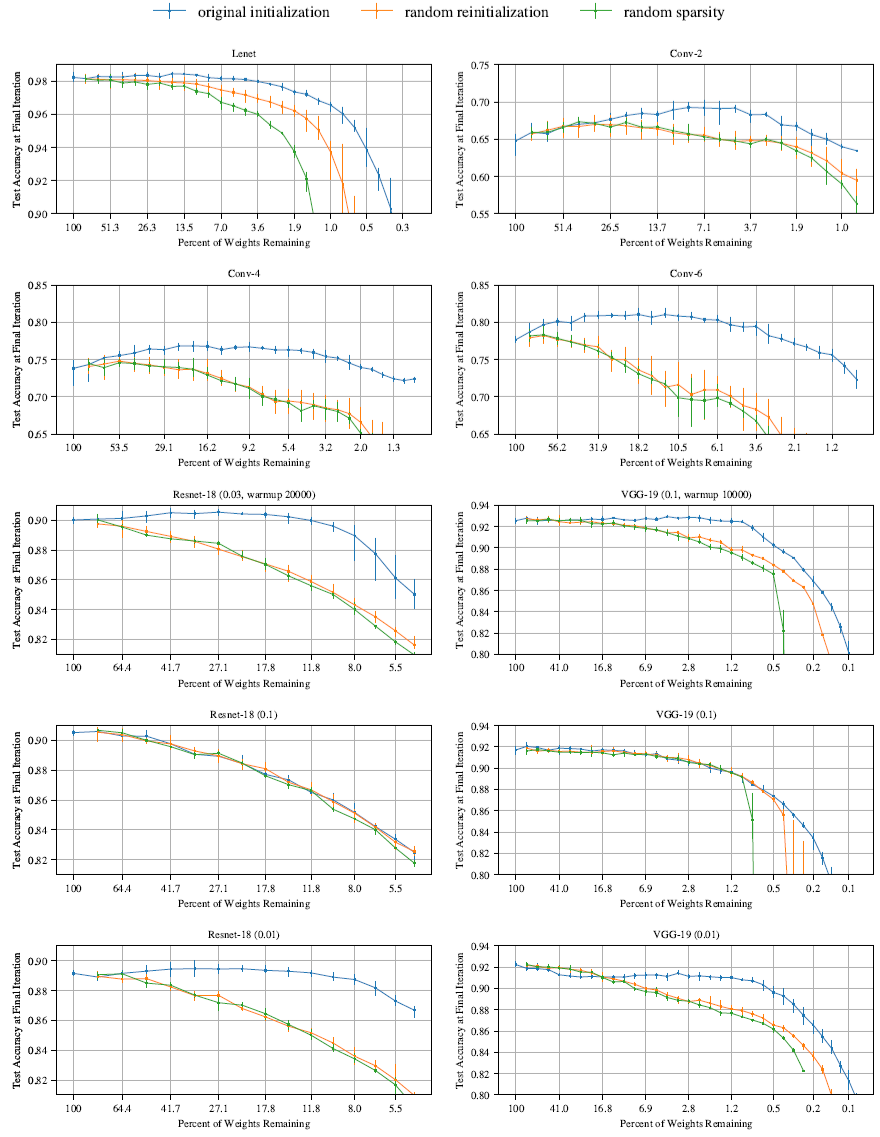
図 14: 本論文で検討した各ネットワークの最終反復におけるテスト精度。
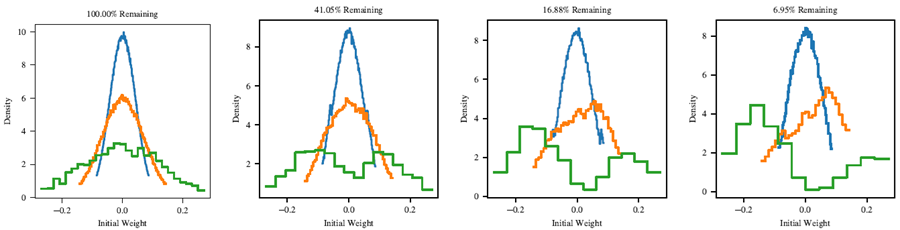
図15: 各グラフのタイトルに指定されたレベルまで枝刈りされた、当りくじにおける初期化値の分布。青、オレンジ、緑の線は、adam最適化器と図2で使用したハイパーパラメータを用いて学習したMNISTのLenetアーキテクチャの第1隠れ層、第2隠れ層、および出力層の分布を示している。分布は、各曲線の下の面積が1になるように正規化されている。
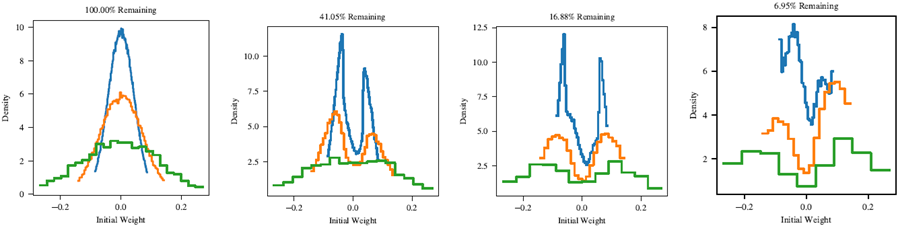
図 16: 図 15 と同じであるが、ネットワークは SGD を使用してレート 0.8 でトレーニングされている。
当りくじの初期化分布のグラフを解釈する別の方法は、次のようになる。小さな重みは小さいまま枝刈りされ、当りくじの一部となることはない。(この特徴付けの唯一の例外は、adamでトレーニングされた当りくじの最初の隠れ層である。)これが事実であれば、低い重みはネットワークにとって重要ではなく、最初から枝刈りできる可能性がある。図18は、この枝刈り戦略を試みた結果を示している。この方法で選択された当りくじは、反復的な枝刈りによって見つけられ、ランダムに再初期化された場合よりもパフォーマンスがさらに低下する。SGDでトレーニングされた当りくじでも同じ実験を試みたところ、同様の結果が得られた。
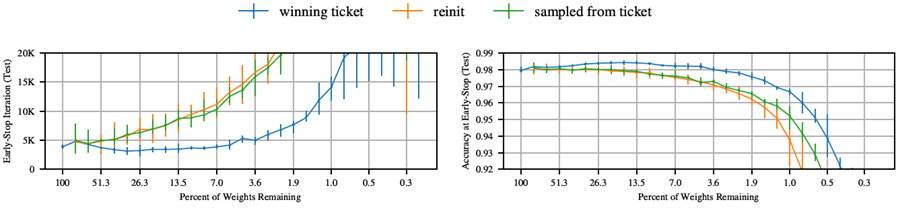
図 17: レイヤーが対応するサイズの当りくじに含まれる初期化の分布からランダムに再初期化された場合の、MNIST の Lenet アーキテクチャの当りくじのパフォーマンス。
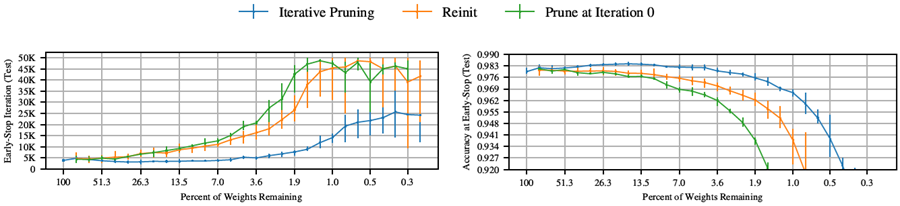
図18: MNISTにおけるLenetアーキテクチャの当りくじのパフォーマンス。ネットワークの学習前に振幅プルーニングを実行した場合。その後、ネットワークはadamで学習される。
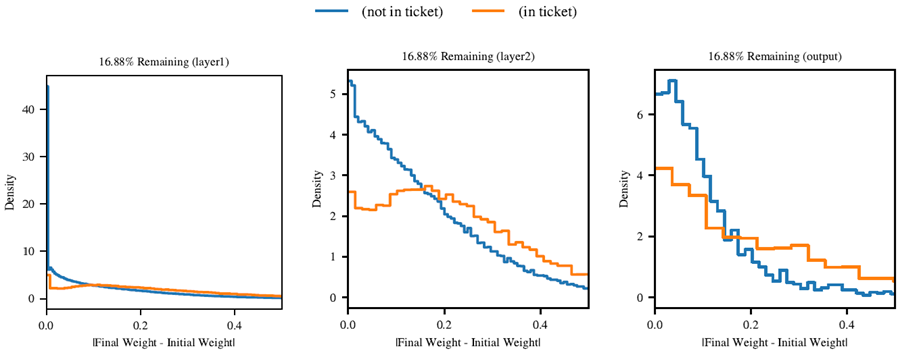
図19: 枝刈りなしネットワークの最初と最後の訓練反復における、ネットワーク内の重みの変化量。青い線は、最終的な当りくじに含まれない重みの変化量の分布を示し、オレンジ色の線は、最終的な当りくじに含まれる重みの変化量の分布を示している。
このサブセクションでは、より大きな最適化プロセスの文脈において、当りくじについて考察する。そのために、当りくじが導出される枝刈り前のネットワークの初期値と最終値の重みを調べ、最終的に当りくじを構成する重みが、ネットワークの他の部分とは異なる特性を示すかどうかを判定する。
初期重みと最終重みの差の大きさについて考察する。当りくじが当選する理由の一つとして、当りくじが既に勾配降下法が最終的に見出した最適値に近いため、当りくじの重みの変化量はネットワークの他の部分よりも小さいことが挙げられる。もう一つの理由として、当りくじは勾配降下法が効率的に最適化できる最適化ランドスケープにおいて適切な位置に配置されているため、当りくじの重みの変化量はネットワークの他の部分よりも大きいことが挙げられる。図19は、当りくじの重みの変化量がネットワークの他の部分よりも大きい傾向にあることを示しているが、これは当りくじが既に最適値に近いという根拠を裏付けるものではない。
2つの分布の間にこのような違いが存在することは注目に値する。この違いに対する一つの説明として、当りくじの概念はニューラルネットワークの最適化において自然なものである可能性が挙げられる。もう一つの説明として、大きさの枝刈りによって、発見される当りくじが、大きさの大きい方向に重みが変化するものへと偏ってしまうことが挙げられる。いずれにせよ、これは当りくじが訓練プロセスの早い段階(あるいは1回の訓練実行後)で識別可能になる可能性を示唆しており、これは反復枝刈りよりも効率的な当りくじ発見方法が存在する可能性を示唆している。
図20は、これらの変化の方向を示している。これは、最終的な重みの大きさと初期の重みの大きさの差、つまり重みが0に近づいたか遠ざかったかをプロットしたものである。一般的に、当りくじの重みは、最終的な当りくじに含まれない重みよりも、大きさが増加する(つまり、0から離れる)可能性が高くなる。
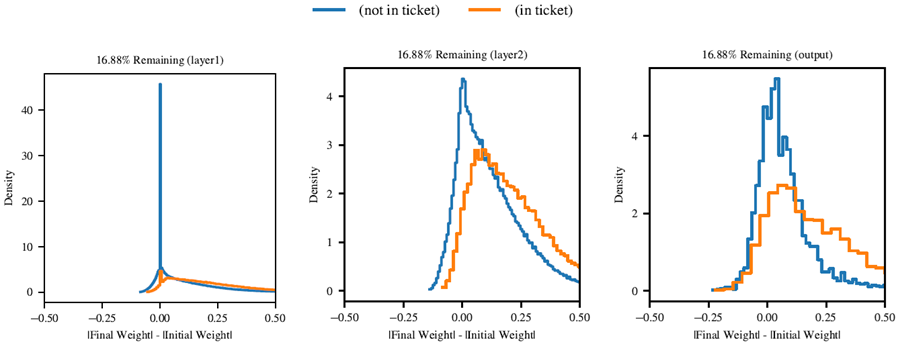
図 20: 枝刈りされていないネットワークの最初のトレーニング反復と最後のトレーニング反復の間での、重みが 0 から離れる大きさ。青い線は、最終的な当りくじに含まれない重みの大きさの分布を示している。オレンジ色の線は、最終的な当りくじに含まれる重みの大きさの分布を示している。
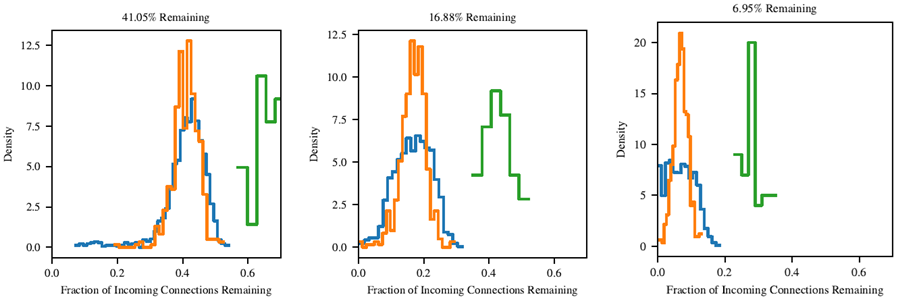
図 21: Adam でトレーニングされた MNIST の Lenet アーキテクチャの各レイヤーの各ノードのプルーニング プロセスを生き残る着信接続の割合。
このサブセクションでは、当りくじの接続性を調べる。一部の隠れユニットは多数の入力接続を維持し、他のユニットは消えていくのか?それとも、ネットワークが刈り込まれてもすべてのユニット間で比較的均一なスパース性を維持するのか?ネットワークユニットの入力接続を調べると、後者のケースであることがわかった。adam と SGD の両方において、各ユニットは、層全体が刈り込まれた量にほぼ比例して、入力接続の数を維持する。図 21 と 22 は、各層の各ノードにおける、刈り込み処理を生き残る入力接続の割合を示している。出力層はネットワークの残りの部分の半分の速度で刈り込まれていることを思い出してもらいたい。これが、出力層がネットワークの他の層よりも多くの接続性を持つ理由である。
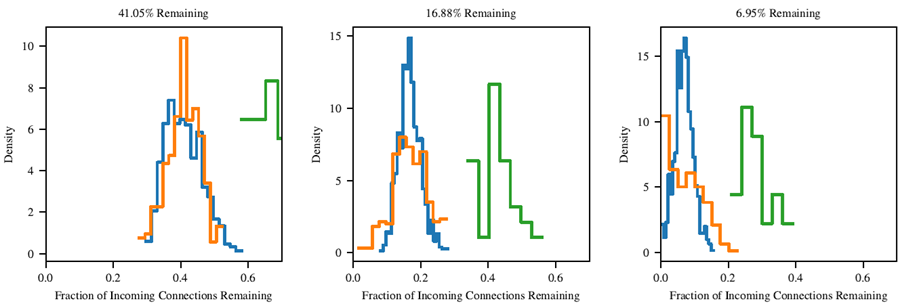
図 22。図 21 と同じであるが、ネットワークは SGD を使用してレート 0.8 でトレーニングされている。
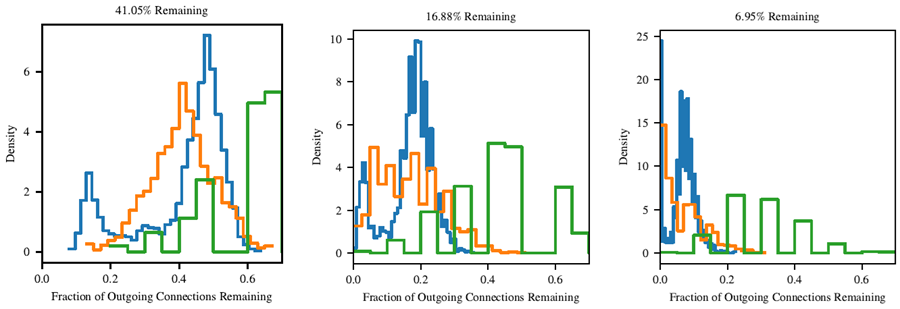
図23。 Adamで学習したMNISTのLenetアーキテクチャの各層の各ノードにおける、枝刈り処理を生き残った出力接続の割合。青、オレンジ、緑の線はそれぞれ、入力層、第1隠れ層、第2隠れ層からの出力接続である。
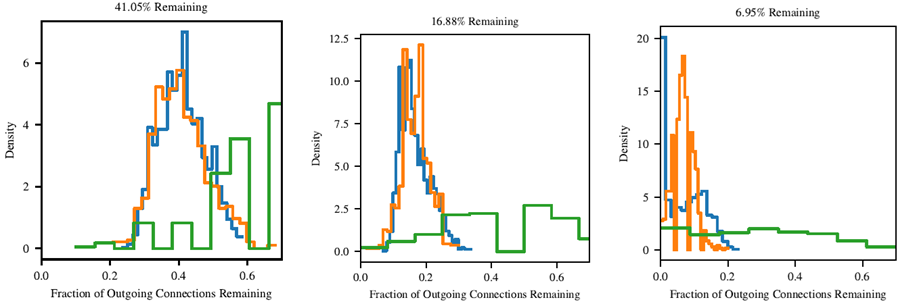
図24。図23 と同じであるが、ネットワークは SGD を使用してレート 0.8 でトレーニングされている。
しかし、出力接続の場合はそうではない。逆に、adam でトレーニングしたネットワークでは、特定のユニットが他のユニットよりもはるかに多くの出力接続を保持している (図 23)。分布は入力接続の場合よりもはるかに滑らかではなく、特定の特徴がネットワークにとって他の特徴よりもはるかに有用であることを示唆している。これは、MNIST のようなタスク、特に入力層における全結合ネットワークでは予想外のことではない。MNIST 画像には中央揃えの数字が含まれているため、エッジ周辺のピクセルはネットワークにとって有益ではない可能性がある。実際、入力層には 2 つのピークがあり、出力接続数が多い入力ユニットの大きなピークと、出力接続数の少ない入力ユニットの小さなピークである。興味深いことに、adam でトレーニングした当りくじでは、入力層の出力接続の分布が SGD でトレーニングしたネットワークよりもはるかに不均一になっている (図 24)。
このサブセクションでは、当りくじが初期化に追加されたガウスノイズに対してどの程度堅牢であるかを検証する。論文本文では、当りくじをランダムに再初期化すると、学習速度が大幅に低下し、最終的なテスト精度が低下することを明らかにした。このサブセクションでは、当りくじを乱す、それほど極端ではない方法について考察する。図25は、当りくじの初期化にガウスノイズを追加した場合の効果を示している。各層のノイズ分布の標準偏差は、その層の初期化の標準偏差の倍数である。図25は、標準偏差が0.5\(\sigma\)、\(\sigma\)、2\(\sigma\)、および3\(\sigma\)のノイズ分布を示している。ガウスノイズを追加すると、当りくじのテスト精度が低下し、学習能力も低下する。これもまた、元の初期化の重要性を示している。ノイズが追加されるにつれて、精度は低下する。しかし、当りくじは驚くほどノイズに対して堅牢である。 0.5\(\sigma\) のノイズを追加しても、当りくじの精度はほとんど変わらない。3\(\sigma\) のノイズを追加した後でも、当りくじはランダム再初期化実験よりも優れた性能を示し続ける。
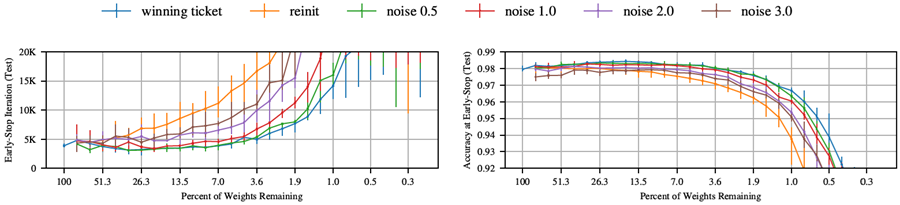
図25。初期化にガウスノイズを加えた場合の、MNISTにおけるLenetアーキテクチャの当りくじのパフォーマンス。各層のノイズ分布の標準偏差は、初期化分布の標準偏差の倍数である。この図では、0.5、1、2、3の倍数を考慮している。
この付録は本論文のセクション2に付随するものであり、セクション2で評価したLenetアーキテクチャのハイパーパラメータ空間を、以下の2つの目的を念頭に検討する。
このセクションでは、MNISTデータセットを用いて、2つの全結合隠れ層と10ユニットの出力層で構成される全結合Lenetアーキテクチャ(LeCun et al., 1998)を考察する。特に断りのない限り、隠れ層はそれぞれ300ユニットと100ユニットで構成される。
MNISTデータセットは、60,000件の学習例と10,000件のテスト例で構成されている。学習セットからランダムに5,000件の検証セットを抽出し、残りの55,000件の学習例を本論文の残りの部分(セクション2を含む)の学習セットとして使用した。本付録全体にわたるハイパーパラメータ選択実験は、早期停止の反復回数と早期停止時の精度を決定するために検証セットを用いて評価される。本論文本文のネットワーク(これらのハイパーパラメータを使用する)の精度は、テストセットを用いて評価される。学習セットは60件のミニバッチとしてネットワークに提示され、各エポックで学習セット全体がシャッフルされる。
特に記載がない限り、各グラフの各線は3つの別々の実験から得られたデータで構成されている。線自体は実験の平均パフォーマンスを示しており、エラーバーは各実験の最小値と最大値を示している。
この付録では、宝くじ実験を反復的に実行する。反復ごとに20%(出力層は10%)の枝刈り率を適用する。この枝刈り率の選択理由については、この付録の後半で説明する。ネットワークの各層は独立して枝刈りされる。宝くじ実験の各反復では、早期停止のタイミングに関わらず、ネットワークは50,000回の訓練反復で学習される。つまり、学習プロセスでは検証データやテストデータは考慮されず、早期停止のタイミングは検証パフォーマンスを検証することで遡及的に決定される。検証とテストのパフォーマンスは100回の反復ごとに評価する。
本論文では、Adam最適化器(Kingma & Ba, 2014)とガウスGlorot初期化法(Glorot & Bengio, 2010)を使用することにした。宝くじ実験では、他のハイパーパラメータを使用することでより印象的な結果が得られるが、主要な結果が手動で選択したハイパーパラメータに依存する程度を最小限に抑えるため、これらの選択は可能な限り汎用的なものに留めている。この付録では、本論文で使用するAdamの学習率を選択する。
さらに、他の最適化アルゴリズム(モメンタム付きSGDとモメンタムなしSGD)、初期化戦略(様々な標準偏差を持つガウス分布)、ネットワークサイズ(隠れ層の大小)、枝刈り戦略(枝刈り速度の高速化と低速化)など、幅広いハイパーパラメータを考慮している。各実験では、選択したハイパーパラメータのみを変化させ、その他のパラメータはデフォルト値(選択した学習率のAdam、ガウスGlorot初期化、隠れ層ユニット数300と100)のままとした。この付録に示すデータは、Lenetアーキテクチャの様々なバリエーションを3,000回以上学習させることで収集された。
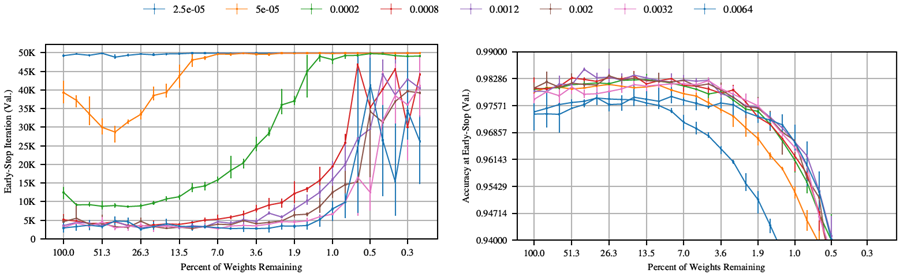
図26。Adam最適化器を用いてMNISTで学習したLenetアーキテクチャにおける反復宝くじ実験における、早期停止反復とその反復における検証精度。様々な学習率で比較した。各線は異なる学習率を表す。
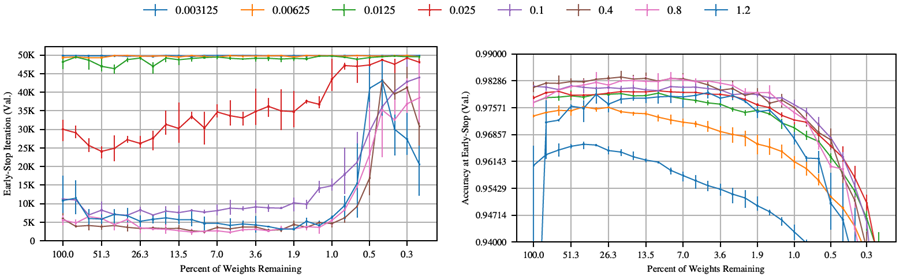
図 27: さまざまな学習率で確率的勾配降下法を使用して MNIST でトレーニングされた Lenet アーキテクチャ上の反復宝くじチケット実験の早期停止反復とその反復での検証精度。
このサブセクションでは、さまざまな学習率で Adam、SGD、モメンタム付き SGD を使用して最適化された Lenet アーキテクチャで宝くじ実験を実行する。
ここでは、本論文の本文でAdamに使用する学習率を選択する。学習率の選択基準は以下のとおり。
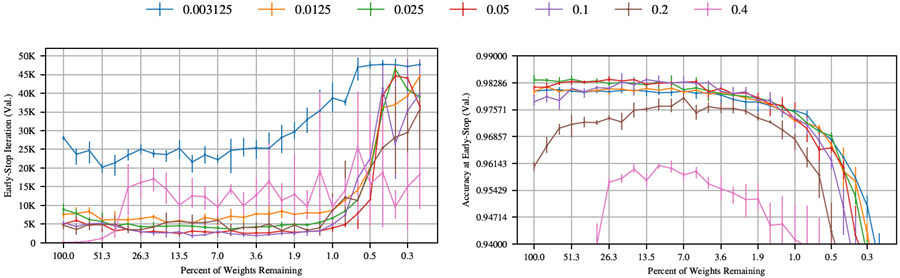
図 28。 さまざまな学習率でモメンタム (0.9) 付き確率的勾配降下法を使用して MNIST でトレーニングされた Lenet アーキテクチャ上の反復宝くじチケット実験の早期停止反復とその反復での検証精度。
図26は、様々な学習率でAdamを用いて最適化されたLenetアーキテクチャを用いて反復宝くじ実験を実行した際の早期停止反復とその反復における検証精度を示している。図26の右側のグラフによると、0.0002から0.002までのいくつかの学習率は、元のネットワークで同様のレベルの検証精度を達成し、ネットワークが剪定されてもそのパフォーマンスを同様のレベルに維持している。これらの学習率のうち、0.0012と0.002は、早期停止時間が最も速く、ネットワークサイズが最小でもそのパフォーマンスを維持する。0.0012を選択したのは、枝刈りされていないネットワークでの検証精度が高いことと、上記の基準(3)を考慮したためである。
これらの学習率のすべてにおいて、当りくじパターン(反復枝刈りによって学習が高速化し、検証精度が向上するパターン)が依然として存在していることに注目してもらいたい。50,000回の反復で早期停止基準を満たさなかった学習率(2.5e-05および0.0064)においても、枝刈りによって精度が向上した。
ここでは、ネットワークがさまざまな学習率で確率的勾配降下法 (SGD) によって最適化されたときの宝くじ実験の挙動を調べる。その結果は図 27 に示されている。宝くじパターンは、50,000 回の反復内で早期停止基準を満たさなかったものも含め、すべての学習率にわたって現れている。SGD 学習率 0.4 と 0.8 は、最高の Adam 学習率 (0.0012 と 0.002) と同数の反復で早期停止に達するが、ネットワークがさらに枝刈りされても (SGD の場合は元のサイズの 1% 未満、Adam の場合は元のサイズの約 3.6% に) このパフォーマンスを維持される。同様に、枝刈りされたネットワークでは、これらの SGD 学習率は最高の Adam 学習率と同等の精度を達成し、ネットワークが Adam 学習率と同じくらい枝刈りされても高い精度を維持する。
ここでは、SGD(モメンタム値0.9)を用いてネットワークを様々な学習率で最適化した場合の宝くじ実験の挙動を調査する。その結果を図28に示す。ここでも宝くじパターンはすべての学習率で現れ、学習率0.025~0.1では、高い検証精度と、最も長い枝刈り反復回数での学習速度が維持されている。学習率0.025は、枝刈り前のネットワークで最高の検証精度を達成する。しかし、枝刈りを行っても検証精度は向上せず、徐々に低下し、学習率が高いほど早期停止に早く到達する。
Lenet上で反復的な宝くじ券実験を実行する際、ネットワークの各層を特定の割合で個別に枝刈りする。つまり、ネットワークを学習させた後、各層の重みのk%(出力層の重みの\(\frac{k}{2}\)%)を枝刈りし、その後、重みを元の初期化値にリセットして再度学習させる。論文本文では、反復的な枝刈りによって単発的な枝刈りよりも当りくじの数が少なくなることを示しており、ネットワークを一度に枝刈りしすぎるとパフォーマンスが低下することを示している。ここでは、\(k\)の異なる値を検討する。
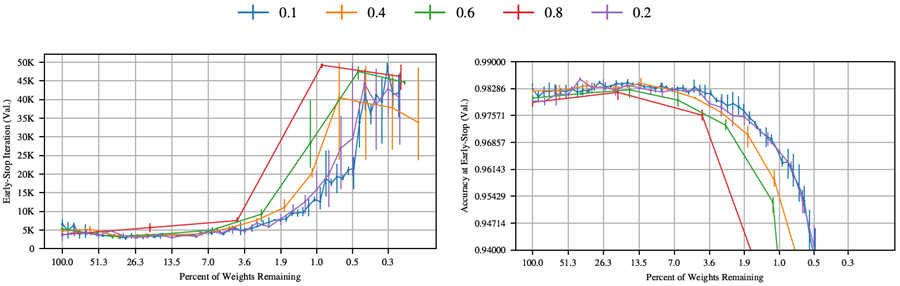
図29: 異なる割合で枝刈りを行った場合の、反復宝くじ実験における早期停止反復とその反復における検証精度。各線は異なる枝刈り率(各訓練反復後に各層から枝刈りされる最小値の重みの割合)を表す。
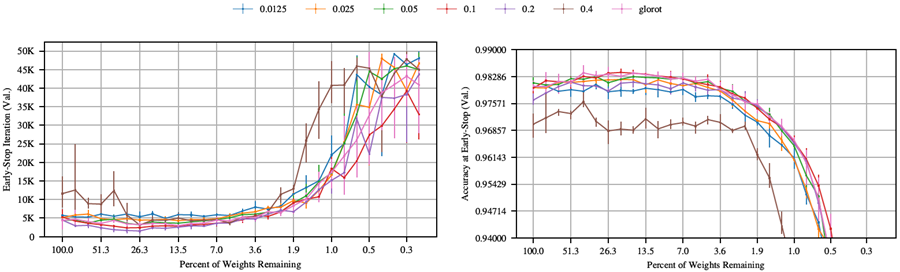
図30: 様々な標準偏差を持つガウス分布で初期化された反復宝くじ実験における早期停止反復とその反復における検証精度。各線は、0を中心とするガウス分布の異なる標準偏差を表している。
図29は、各枝刈り反復で枝刈りされるネットワークの量が、早期停止時間と検証精度に与える影響を示している。早期停止時の学習速度と検証精度には、最低の枝刈り率(0.1および0.2)と高い枝刈り率(0.4以上)とで明らかな違いがある。最低の枝刈り率は高い検証精度に達し、より小さなネットワークサイズでもその検証精度を維持する。また、より小さなネットワークサイズでも高速な早期停止時間を維持する。本論文の本文およびこの付録全体での実験では、枝刈り率0.2を使用している。これにより、0.1の場合とほぼ同等の精度と学習速度を維持しながら、より小さなネットワークサイズに到達するために必要なトレーニング反復回数を削減できる。
Lenetのすべての実験において、出力層はネットワークの他の部分の半分の速度で枝刈りを行った。出力層は非常に小さいため(Lenetアーキテクチャ全体の重み266,000個のうち1,000個)、出力層の枝刈りは他の層よりもはるかに早く収穫逓減点に達することがわかった。
ここまで、ネットワークの初期化スキームとしてガウスGlorot(Glorot & Bengio, 2010)のみを検討してきた。図30は、様々な標準偏差を持つガウス分布からLenetアーキテクチャを初期化しながら宝くじ実験を実行したものである。ネットワークは、先ほど選択した学習率でAdamを用いて最適化されている。当りくじパターンは、すべての標準偏差にわたって現れ続けている。標準偏差0.1のガウス分布から初期化した場合、Lenetアーキテクチャは高い検証精度と低い早期停止時間を最も長く維持し、Glorotで初期化されたネットワークのパフォーマンスとほぼ一致した。
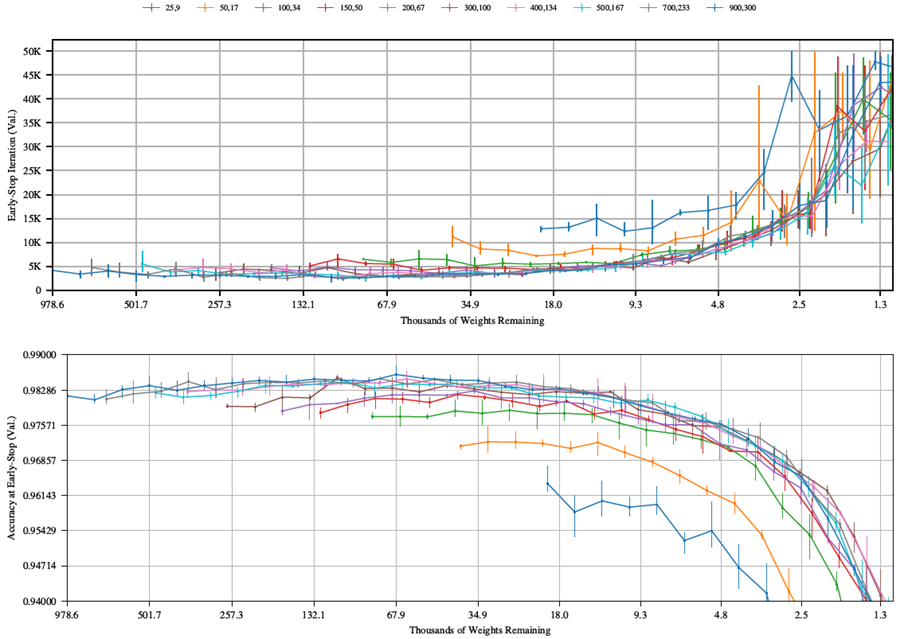
図31。様々な層サイズのLenetアーキテクチャにおける反復宝くじチケット実験における、早期停止反復とその反復における検証精度。各線のラベルは、ネットワークの1層目と2層目の隠れ層のサイズである。すべてのネットワークはガウスGlorotで初期化され、Adam(学習率0.0012)で最適化されている。このグラフのx軸は残りの重みの数を示しているが、このセクションの他のすべてのグラフは残りの重みの割合を示している。
このセクション全体を通して、第1隠れ層に300ユニット、第2隠れ層に100ユニットを配置したLenetアーキテクチャを検討してきた。図31は、Lenetアーキテクチャにおいて、他のいくつかの層サイズにおける早期停止反復とその反復における検証精度を示している。テストしたすべてのネットワークにおいて、第1隠れ層と第2隠れ層のユニットの比率は3:1を維持している。
宝くじ仮説は、ネットワークの規模に関する一連の疑問を自然に呼び起こす。一般化すると、これらの疑問は次のような形になる傾向がある。宝くじ仮説によれば、より多くのサブネットワークを含む大規模なネットワークは、「より良い」当りくじを見つけるのだろうか?この疑問の一般性に沿って、いくつかの異なる答えが考えられる。
当りくじをそれが達成する精度で評価すると、大規模なネットワークの方がより良い当りくじを見つける。図 31 の右のグラフは、特定の数の重み (つまり、x 軸上の任意の特定のポイント) に対して、最初に規模が大きかったネットワークから得られた当りくじの方が精度が高くなることを示している。言い換えると、精度の観点から、線はネットワーク サイズが増加する順に下から上に向かってほぼ配置されている。大規模なネットワークにはより多くのサブネットワークがあるため、勾配降下法によってより良い当りくじが見つかった可能性がある。あるいは、最初に規模が大きかったネットワークは、より小さなネットワークと同じ数の重みに刈り込んだ場合でもユニットが多く、つまり、最初に規模が小さかったネットワークでは表現できない疎なサブネットワーク構成を含めることができることを意味する。
当りくじを早期停止までの所要時間で評価すると、大規模ネットワークの優位性は低下する。図31の左のグラフは、一般的に、初期サイズが異なるネットワーク間で、同じ重み数に枝刈りされた早期停止の反復回数に大きな差がないことを示している。さらに詳しく調べると、当初規模が大きかったネットワークから得られた当りくじは、当初規模が小さかったネットワークから得られた当りくじよりもわずかに速く学習する傾向があるが、これらの差はわずかである。
当りくじを、元のネットワークと同じ精度に戻るサイズで評価すると、大規模ネットワークに優位性はない。図31の右のグラフは、初期のネットワークサイズに関わらず、当たりチケットを約9,000から15,000の重みに刈り込むと、元のネットワークと同じ精度に戻ることを示している。
この付録は、本論文のセクション3に付随するものである。本論文のセクション3で評価したConv-2、Conv-4、Conv-6アーキテクチャの最適化アルゴリズムとハイパーパラメータの空間を考察する。付録Gと同じ2つの目的、すなわち本論文で使用したハイパーパラメータの説明と、他のハイパーパラメータの選択における宝くじチケット実験の評価を目的としている。
Conv-2、Conv-4、および Conv-6 アーキテクチャは、CIFAR10 (Krizhevsky & Hinton, 2009) データセット用にスケールダウンされた VGG (Simonyan & Zisserman, 2014) ネットワーク アーキテクチャの派生版である。VGG と同様に、ネットワークは一連のモジュールで構成されている。各モジュールには 3x3 畳み込みフィルターの 2 つの層があり、その後にストライド 2 の Maxpool 層が続く。すべてのモジュールの後に、サイズ 256 の 2 つの全結合層があり、その後にサイズ 10 の出力層が続く。VGG では、全結合層のサイズは 4096 で、出力層のサイズは 1000 である。VGG と同様に、最初のモジュールには各層に 64 の畳み込みがあり、2 番目は 128、3 番目は 256 といった具合です。Conv-2、Conv-4、および Conv-6 アーキテクチャには、それぞれ 1、2、3 つのモジュールがある。
CIFAR10データセットは、32x32カラー(3チャネル)の学習用データ50,000件とテスト用データ10,000件で構成されている。学習用データからランダムに5,000件の検証用データセットを抽出し、残りの45,000件の学習用データを本論文の残りの部分で学習用データセットとして使用した。本付録全体にわたるハイパーパラメータ選択実験は検証用データセットを用いて評価し、本論文本文の例(これらのハイパーパラメータを使用するもの)はテスト用データセットを用いて評価した。学習用データセットは、60件のミニバッチとしてネットワークに提示され、各エポックで学習用データセット全体がシャッフルされる。
Conv-2、Conv-4、およびConv-6ネットワークは、ガウスGlorot初期化(Glorot & Bengio, 2010)で初期化され、図2に示されている反復回数で学習される。学習反復回数は、重度に枝刈りされたネットワークでも指定された時間内で学習できるように選択された。ドロップアウト実験では、ドロップアウト正規化ネットワークが十分な学習時間を確保するために、学習反復回数を3倍に増やす。これらのネットワークはAdamを用いて最適化し、各ネットワークの学習率は本付録で決定する。
MNIST実験と同様に、検証とテストのパフォーマンスは遡及的にのみ考慮され、宝くじ実験の進行には影響しない。検証とテストの損失と精度は、100回の訓練反復ごとに測定する。
このセクションの各グラフの各線は、3つの個別の実験の平均を表し、エラーバーはその時点での各実験の最小値と最大値を示している。(論文本文の実験は5回実施されている。)
畳み込み層と全結合層は異なる速度で枝刈りすることができる。この付録では、各ネットワークの枝刈り速度を選択する。出力層は、付録Gで説明する理由により、全結合層の半分の速度で枝刈りされる。
このサブセクションでは、さまざまな学習率で Adam によって最適化された Conv-2、Conv-4、および Conv-6 アーキテクチャで宝くじチケット実験を実行する。
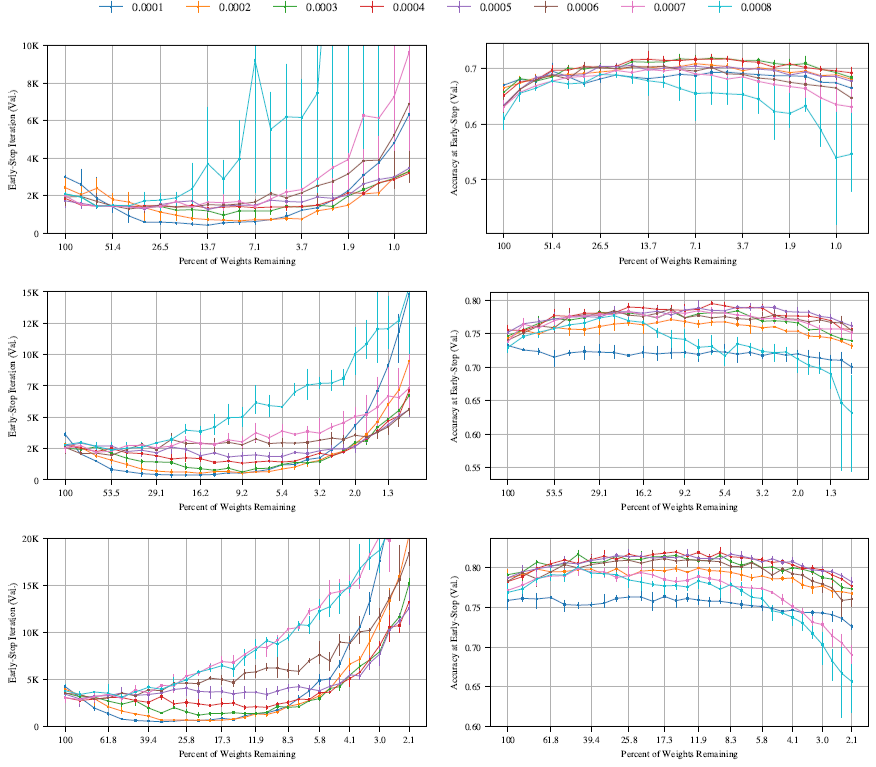
図32。 Adamオプティマイザーを用いて様々な学習率で学習したConv-2(上)、Conv-4(中)、Conv-6(下)アーキテクチャにおける反復宝くじ実験における早期停止反復とその反復における検証精度。各線は異なる学習率を表している。
ここでは、本論文でAdamに用いる学習率を選択する。学習率の選択基準は付録Gと同じある。訓練の反復回数を最小限に抑え、早期停止時の精度を最大化し、可能な限り少ないパラメータで当たりチケットを見つけ、他の様々な実験に適用できる程度に保守的な値を維持する。
図32は、Conv-2(上)、Conv-4(中)、Conv-6(下)アーキテクチャで反復宝くじ実験を実行した結果を示している。各ネットワークの枝刈り率はまだ決定していないため、全結合層を1回あたり20%、畳み込み層を1回あたり10%、出力層を1回あたり10%で一時的に枝刈りした。このハイパーパラメータ空間の部分については、後のサブセクションで考察する。
Conv-2 では、初期検証精度が最も高く、最長時間にわたって高い検証精度と短い早期停止時間の両方を維持し、最速の早期停止時間に到達する学習率 0.0002 を選択する。この学習率では、ネットワークが元のサイズの 3% に削減されたときに、検証精度が 3.3 パーセント ポイント向上する。0.0004 などの他の学習率では、初期検証精度は低くなるが (65.2% vs. 67.6%)、最終的には検証精度の絶対レベルが高くなる (71.7%、6.5 パーセント ポイントの増加 vs. 70.9%、3.3 パーセント ポイントの増加)。ただし、学習率 0.0002 では、早期停止時間の比例減少が最も大きく、4.8 倍である (元のネットワーク サイズの 8.8% に削減した場合)。
Conv-4では、学習率0.0003を選択した。これは、初期検証精度が最も高く、枝刈り後も高い検証精度と高速な早期停止時間を維持し、検証精度の向上(重みの残り5.4%で3.7パーセントポイント向上し、78.6%に)と早期停止時間の改善(重みの残り11.1%で4.27倍)のバランスが取れている。他の学習率では、より高い検証精度(重みの残り5.4%で0.0004、3.6パーセントポイント向上し、79.1%に)に達するか、早期停止時間の改善(重みの残り9.2%で0.0002、5.1倍)が見られるが、両方ではない。
Conv-6では、Conv-4と同様の理由から学習率0.0003を選択した。重みの9.31%が残っている場合、検証精度は2.4パーセントポイント向上して81.5%となり、枝刈りによって11.9%になった場合、早期停止時間は2.61倍改善される。学習率0.0004では、重みの15.2%が残っている場合、最終的な検証精度は高く(2.7パーセントポイント向上して81.9%)、早期停止時間の改善幅は小さくなる。学習率0.0002では、重みの19.7%が残っている場合、早期停止時間の改善幅は大きくなるが(6.26倍)、全体的な検証精度は低くなる。
ほぼすべての学習率の組み合わせにおいて、宝くじのパターン(宝くじ実験の過程で早期終了時間が維持または短縮され、検証精度が維持または向上する)が維持されていることがわかる。このパターンは、学習率を最も高く設定した場合に維持されない。早期停止時間は、Conv-2またはConv-4の場合にほんの短時間しか短縮されず、Conv-6の場合には全く短縮されず、精度もほんの短時間しか向上しない(3つのネットワークすべて)。このパターンは、セクション4で観察されたものと類似している。つまり、学習率を最も高く設定した場合、反復的な枝刈りアルゴリズムは当選チケットを見つけることができない。
ここでは、Conv-2、Conv-4、Conv-6 ネットワークをさまざまな学習率で確率的勾配降下法 (SGD) で最適化した場合の宝くじ実験の挙動を調べる。その結果は図 33 に示されている。一般に、これらのネットワーク (特に Conv-2 と Conv-4) は、SGD と Glorot 初期化を使用してトレーニングするのが難しいことがわかっている。図 33 が示すように、枝刈りしていないネットワークが Adam でトレーニングした場合の同じネットワークの検証精度と一致する SGD 学習率を見つけることができなかった。SGD でトレーニングした枝刈りしていないネットワークは、せいぜい 2~3 パーセント ポイント精度が低かった。図 32 よりも高い学習率では、枝刈りしていないネットワークをトレーニングするときに勾配が爆発する傾向があり、低い学習率では、ネットワークがまったく学習できないことがよくあった。
図示したすべての学習率において、当りくじを発見した。いずれの場合も、早期停止時間は枝刈りによって当初は減少したが、最終的には再び増加した。これは他の宝くじ実験と同様である。Conv-6ネットワークも他の実験と同様の精度パターンを示し、検証精度は枝刈りによって当初は増加したが、最終的には再び減少した。
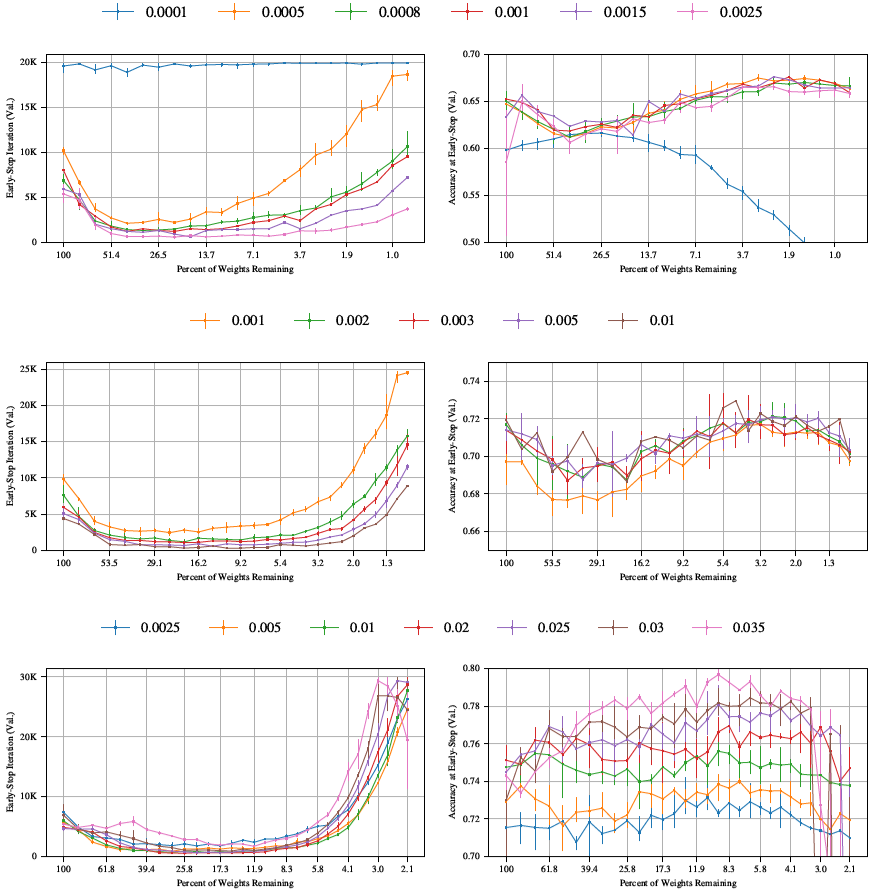
図33。SGDを用いて様々な学習率で学習したConv-2(上)、Conv-4(中)、Conv-6(下)アーキテクチャにおける反復宝くじ実験における早期停止反復とその反復における検証精度。各線は異なる学習率を表している。各グラフの凡例はグラフの上に示されている。
しかし、Conv-2 および Conv-4 アーキテクチャは、本稿の他の実験とは異なる検証精度パターンを示した。精度は当初、枝刈りとともに低下したが、ネットワークがさらに枝刈りされるにつれて上昇し、最終的には枝刈りされていないネットワークの精度と同等かそれを上回った。最終的に元のネットワークの精度を超えたとき、枝刈りされたネットワークは元のネットワークとほぼ同じかそれより少ない反復で早期停止に達し、我々の定義による当りくじを構成した。興味深いことに、このパターンは、より遅い SGD 学習速度の Conv-6 ネットワークでも発生した。これは、図 32 よりも Conv-2 および Conv-4 の学習速度が速いと、通常の宝くじ精度パターンが再び現れる可能性があることを示唆している。残念ながら、これらの高い学習速度では、枝刈りされていないネットワークで勾配が爆発し、これらの実験を実行できなかった。
ここでは、SGD(モメンタム値0.9)を用いてネットワークを最適化した際の宝くじ実験の挙動を、様々な学習率で検証する。その結果を図34に示す。全体的には宝くじパターンが引き続き適用され、ネットワークの枝刈りが進むにつれて早期停止時間が短縮し、精度が向上する。ただし、このパターンには2つの例外がある。
畳み込みネットワークアーキテクチャでは、畳み込み層と全結合層で異なる刈り込み率を選択する。Conv-2およびConv-4アーキテクチャでは、畳み込みパラメータはモデル全体のパラメータ数に占める割合が比較的小さい。畳み込みをよりゆっくりと刈り込むことで、パフォーマンスを維持しながらモデルをさらに刈り込むことができる可能性が高くなる。言い換えれば、すべての層が均等に刈り込まれた場合、畳み込み層がボトルネックとなり、パラメータ数が少なくても学習可能なモデルを見つけるのが難しくなると仮定している。Conv-6の場合は逆のことが当てはまる可能性がある。パラメータの約3分の2が畳み込み層にあるため、全結合層の刈り込みがボトルネックになる可能性がある。
このセクションでハイパーパラメータを選択する基準は、検証精度を元の精度以上に保ち、早期停止時間を元のネットワークと同じかそれ以下に維持しながら、ネットワークが可能な限り低いパラメータ数に到達できるようにする枝刈り率の組み合わせを見つけることである。
図 35 は、Conv-2 (上)、Conv-4 (中央)、および Conv-6 (下) に対して、さまざまな剪定率の組み合わせで反復宝くじチケット実験を実行した結果を示している。
我々の基準に基づき、畳み込み反復枝刈り率を、Conv-2では10%、Conv-4では10%、Conv-6では15%とした。各ネットワークにおいて、10%から20%の間の任意の率が妥当であるように思われた。全ての畳み込み枝刈り率において、宝くじパターンは引き続き出現した。
ドロップアウト付きのConv-2、Conv-4、およびConv-6アーキテクチャをトレーニングするために、セクションH.2の演習を繰り返して適切な学習率を選択した。図32は、ドロップアウトとAdamをさまざまな学習率でConv-2(上)、Conv-4(中央)、およびConv-6(下)に対して反復宝くじチケット実験を実行した結果を示している。ドロップアウト付きでトレーニングされたネットワークは学習に時間がかかるため、ドロップアウトなしの実験の3倍の反復回数で各アーキテクチャをトレーニングした。つまり、Conv-2の場合は60,000回、Conv-4の場合は75,000回、Conv-6の場合は90,000回である。セクションH.4で決定したレートでこれらのネットワークを反復的に枝刈りした。
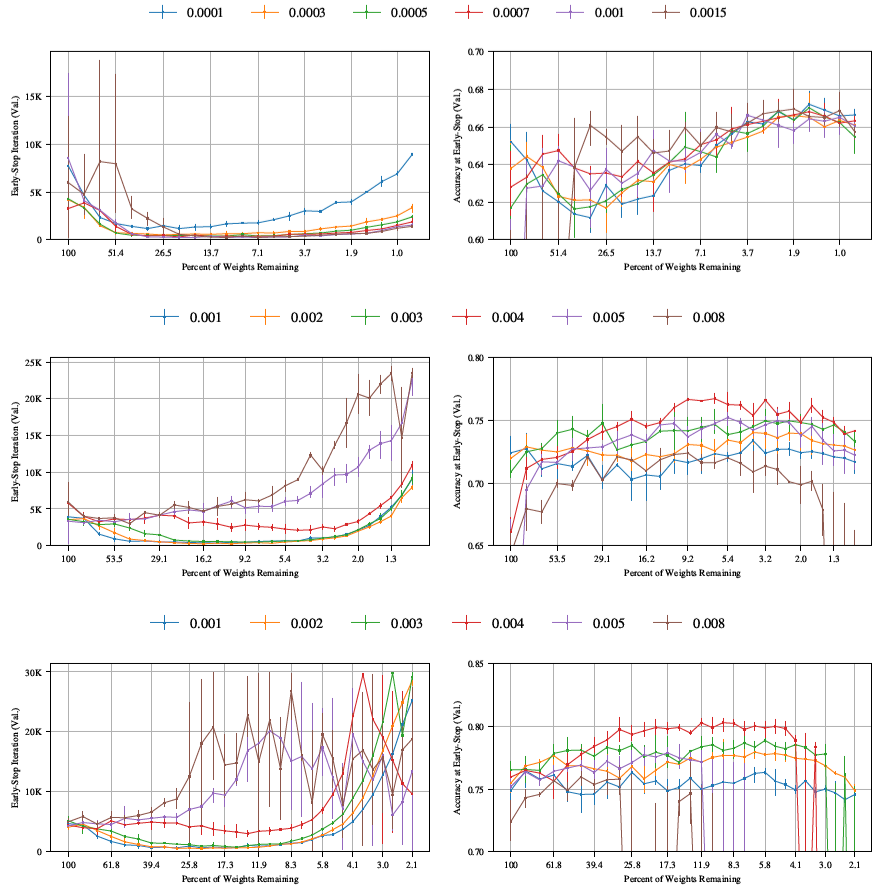
図34。SGD(モメンタム値0.9)を用いて様々な学習率で学習したConv-2(上)、Conv-4(中)、Conv-6(下)アーキテクチャにおける反復宝くじ実験の早期終了反復とその反復における検証精度。各線は異なる学習率を表している。各グラフの凡例はグラフの上にある。不安定で大きなエラーバー(大きな垂直線)を含む線は、一部の実験が効果的な学習に失敗し、精度が非常に低く、早期停止時間が非常に長くなっていることを示している。これらの実験は、線が描く平均値を減少させ、エラーバーを大幅に広げる。
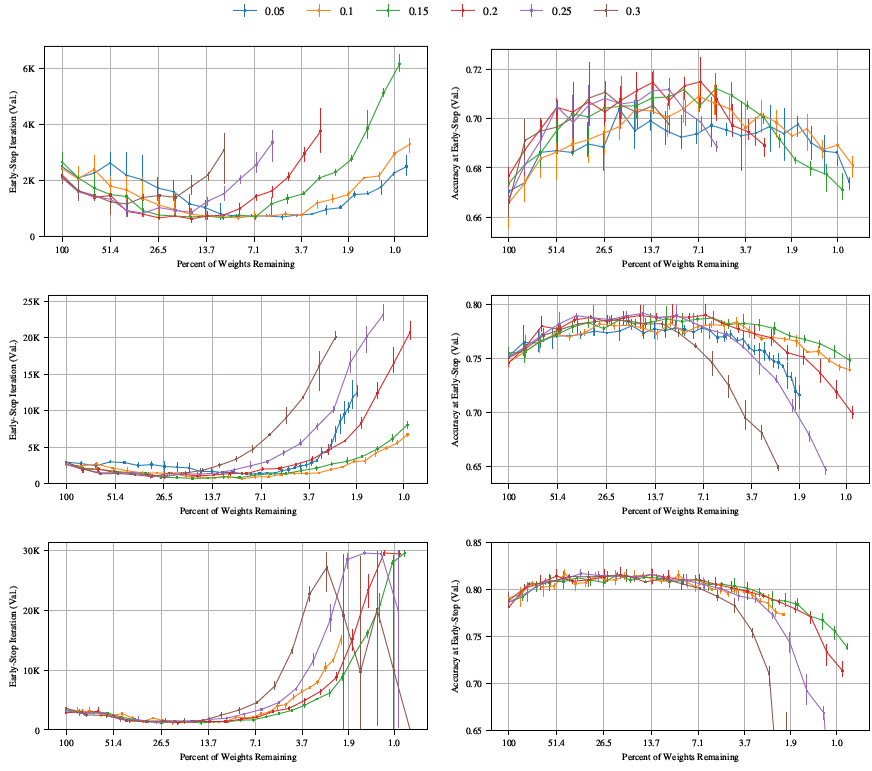
図35: Conv-2(上)、Conv-4(中)、Conv-6(下)アーキテクチャにおける反復宝くじチケット実験の早期停止反復回数と、その反復回数における検証精度。全結合層の反復プルーニング率は20%。各線は畳み込み層の異なる反復プルーニング率を表す。
Conv-2 ネットワークは、ドロップアウトがあると一貫してトレーニングするのが難しいことが判明した。図 36 の右上のグラフには、多くの学習率、特に宝くじ実験の初期段階での多くの学習率に対する広いエラー バーと低い平均精度が含まれている。これは、トレーニング実行の一部またはすべてが学習に失敗したことを示している。他の結果と平均化すると、グラフで前述したパターンが生成された。学習率 0.0001 では、3 つの試行すべてが 26.5% を超えるまで生産的に学習しなかった。26.5% を超えると、3 つの試行すべてが学習を開始した。学習率 0.0002 では、反復的なプルーニングが数回完了するまで、試行の一部が生産的に学習できなかった。学習率 0.0003 では、3 つのネットワークすべてがすべてのプルーニング レベルで生産的に学習した。学習率 0.0004 では、1 つのネットワークが時折学習に失敗した。ネットワークが最も頻繁に生産的に学習し、最も高い初期精度を達成できると思われる学習率 0.0003 を選択した。
特定の学習率(例えば0.0001)では学習できなかったネットワークが、宝くじ実験(つまり、トレーニング、枝刈り、リセットを繰り返す)を数回繰り返した後、最終的に学習を開始したことは興味深い点である。この現象が完全に枝刈りによるものなのか(つまり、ランダムな重みの集合を削除すると、ネットワークは学習しやすい構成になる)、それともネットワークの精度向上が見られなかったとしても、ネットワークのトレーニングによって枝刈りに有用な情報が得られたのかを調査する価値がある。
Conv-4 アーキテクチャと Conv-6 アーキテクチャの両方において、わずかに遅い学習率 (0.0003 ではなく 0.0002) により、宝くじ実験中にネットワークが剪定される際に最高の持続精度と最速の持続学習に加えて、枝刈りされていないネットワークで最高の精度が得られる。
ドロップアウトありの場合、枝刈りなしConv-4アーキテクチャの平均検証精度は77.6%に達する。これは、ドロップアウトなしでトレーニングされた枝刈りなしConv-4ネットワークと比較して2.7パーセントポイントの改善であるが、当りくじが達成した最高の平均検証精度より1パーセントポイント低い値である。ドロップアウトありでトレーニングされた当りくじは、枝刈りを7.6%にした場合、平均検証精度が82.6%に達する。早期停止時間は最大1.58倍(7.6%に枝刈りした場合)改善されるが、ドロップアウトなしで得られた当たりチケットの4.27倍の改善よりも小さい値である。
ドロップアウトありの場合、枝刈りなしのConv-6アーキテクチャは平均検証精度が81.3%に達し、ドロップアウトなしの場合の精度より2.2パーセントポイント向上した。これは、ドロップアウトなしでトレーニングし、枝刈りを9.31%にまで行ったConv-6の平均精度81.5%とほぼ一致する。ドロップアウトありでトレーニングした当りくじはこれらの数値をさらに向上させ、枝刈りを10.5%にまで行った場合でも平均検証精度は84.8%に達する。早期停止時間の改善はドロップアウトなしの場合ほど劇的ではなく、ネットワークを15.1%に枝刈りすると平均1.5倍の改善となる。
テストしたすべての学習率において、宝くじパターンは概ね精度に反映され、ネットワークの枝刈りが進むにつれて精度が向上した。しかし、すべての学習率で早期停止時間の短縮が見られるわけではない。対照的に、Conv-2では、他の宝くじ実験で見られるような早期停止時間の明確な改善は見られなかった。同様に、Conv-4とConv-6の高学習率は、約40%まで枝刈りが行われるまで元の早期停止時間を維持し、そこから早期停止時間は着実に増加した。
図37は、畳み込みのみ(緑)、全結合層のみ(オレンジ)、両方(青)の刈り込みの効果を示している。x軸は、畳み込みと全結合層の刈り込みがネットワーク全体に与える影響を強調するために、残りのパラメータ数を示している。3つのケースすべてにおいて、畳み込みのみの刈り込みはテスト精度の向上と学習速度の向上につながる。一方、全結合層のみの刈り込みは、一般的にテスト精度の低下と学習速度の低下を引き起こす。ただし、畳み込みのみの刈り込みでは、ネットワーク全体のパラメータ数を削減する効果には限界がある。これは、Conv-2、Conv-4、Conv-6において、全結合層がパラメータの99%、89%、35%を占めているためである。
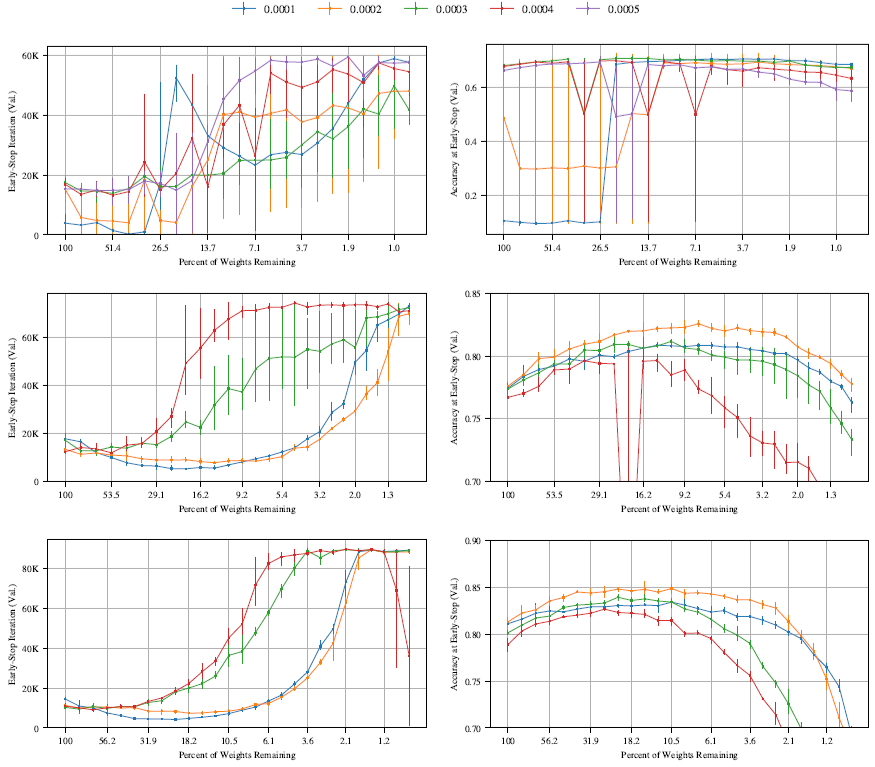
図36: ドロップアウトとAdamオプティマイザーを用いて様々な学習率で学習したConv-2(上)、Conv-4(中)、Conv-6(下)アーキテクチャにおける反復宝くじ実験の早期停止反復とその反復における検証精度。各線は異なる学習率を表している。
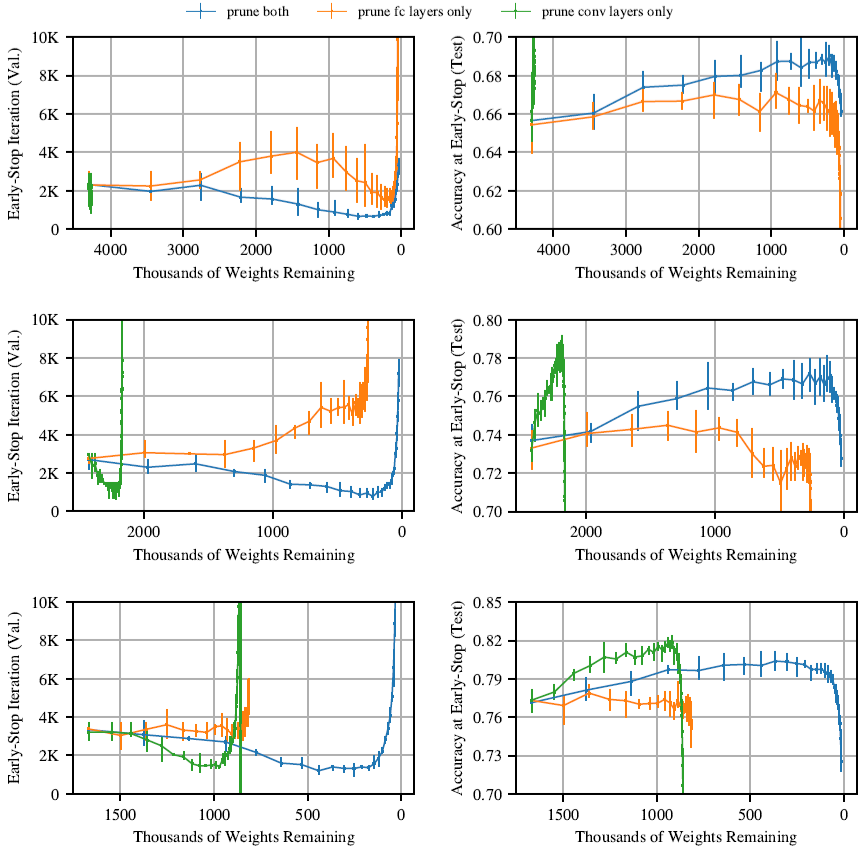
図37: Conv-2 (上)、Conv-4 (中)、Conv-6 (下) ネットワークにおける、畳み込み層のみを刈り込んだ場合、全結合層のみを刈り込んだ場合、および畳み込み層と全結合層の両方を刈り込んだ場合の早期停止反復処理と精度。X軸は残存パラメータ数を示しており、FC層と畳み込み層を個別に刈り込んだ場合のネットワーク全体への相対的な寄与を見ることができる。
この付録は、セクション 4 の VGG-19 および Resnet-18 の実験に付随するものである。これらのネットワークに使用するプルーニング スキーム、トレーニング レジーム、およびハイパーパラメータについて詳しく説明する。
LenetおよびConv-2/4/6アーキテクチャを用いた実験では、各層のパラメータの一部を個別にプルーニング(層単位のプルーニング)した。VGG-19およびResnet-18を用いた実験では、グローバルプルーニングを行った。つまり、重みの元となる層に関係なく、畳み込み層のすべての重みをまとめてプルーニングした。
図38 (VGG-19) と図39 (Resnet-18) は、セクション4のハイパーパラメータについて、グローバルプルーニング (実線) とレイヤーワイズプルーニング (破線) によって見つかった当りくじを比較している。学習率 0.1 で VGG-19 をトレーニングし、反復回数を 10,000 回にウォームアップした場合、レイヤーワイズプルーニングでは \(P_m\geq\) 6.9% のときに当りくじが見つかるのに対し、グローバルプルーニングでは \(P_m\geq\) 1.5% のときに当りくじが見つかる。他のハイパーパラメータについても、レイヤーワイズプルーニングの方がグローバルプルーニングよりも早く精度が低下する。Resnet-18 でも、グローバルプルーニングではレイヤーワイズプルーニングよりも小さな当りくじトが見つかるが、その差は VGG-19 ほど極端ではない。
セクション4では、より深いネットワークにおけるグローバルプルーニングの有効性の根拠について議論した。要約すると、これらの深層ネットワークでは、層ごとにパラメータ数が大きく異なる(特にVGG-19では顕著)。層ごとにプルーニングを行うと、パラメータ数が少ない層が、より小さな当りくじを見つける能力のボトルネックになると考えられる。
レイヤーワイズプルーニングとグローバルプルーニングのどちらを使用した場合でも、セクション4のパターンは維持される。学習率0.1では、反復プルーニングではどちらのネットワークでも当りくじは見つからない。学習率0.01では当りくじパターンが再び現れ、ウォームアップでより高い学習率でトレーニングすると、反復プルーニングで当りくじが見つかる。図40(VGG-19)と41(Resnet-18)は、セクション4の図7(VGG-19)と図8(Resnet-18)と同じデータを、グローバルプルーニングではなくレイヤーワイズプルーニングで示している。グラフはセクション4と同じ傾向を示しているが、最小の当りくじはグローバルプルーニングで見つかった当りくじよりも大きくなっている。
VGG19アーキテクチャは、Simonyan & Zisserman (2014) によってImagenet向けに最初に設計された。ここで使用するバージョンは、Liu et al. (2019) によってCIFAR10向けに改良されたものである。ネットワークは図2に示すように構成されている。3x3畳み込み層を5グループ備え、最初の4つのグループには最大プーリング(ストライド2)が、最後のグループには平均プーリングが続く。ネットワークには、平均プーリングの結果を出力に接続する最後の密な層が1つある。
我々は付録Iに記載されているresnet18のトレーニング手順にほぼ従う。 We largely follow the training procedure for resnet18 described in Appendix I:
ネットワークの畳み込み層を反復ごとに 20% の割合で全体的に枝刈りするが、出力層の 5120 個のパラメータは枝刈りしない。
Liu et al. (2019) は初期枝刈り率0.1を使用している。我々はこの学習率と学習率0.01の両方でVGG19を学習する。
Resnet-18アーキテクチャは、Heら(2016)によって初めて導入された。このアーキテクチャは、図2に示すように、合計20層で構成されている。畳み込み層、それに続く9組の畳み込み層(各組の周囲に残差結合を持つ)、平均プーリング、そして全結合出力層である。
我々はHe et al. (2016)の実験設計に従う。
畳み込みは、反復ごとに20%の割合でグローバルに枝刈りされる。残差接続をダウンサンプリングするために使用される2560個のパラメータと、全結合出力層の640個のパラメータは、ネットワーク全体から見て非常に小さいため、枝刈りは行わないん。
セクション4では、VGG-19とResnet-18において、ネットワークの学習に用いられる典型的な高い学習率(0.1)では反復枝刈りが当りくじを見つけることができないものの、より低い学習率(0.01)では当りくじを見つけることができることを観察した。図42と図43は、他のいくつかの学習率を示している。一般的に、反復枝刈りはどちらのネットワークにおいても、0.01を超える学習率では当りくじを見つけることができない。より高い学習率では、元の初期化値を持つ枝刈りネットワークは、ランダムに再初期化した場合と比べてパフォーマンスが向上しない。
セクション4では、初期学習率に線形ウォームアップを追加することで、VGG-19およびResnet-18において、より高い学習率で当りくじ(ひいてはより高い精度の当りくじ)を見つけることができるようになることを説明する。図44と図45では、ウォームアップを実行する反復回数kについて検討する。
VGG-19では、ネットワークを元の学習率(0.1)で学習させた場合、反復枝刈りによって当りくじを識別できるkの値を見つけることができた。Resnet-18では、ウォームアップによって学習率を0.01から0.03まで上げることはできたが、それ以上上げることはできなかった。したがって、kの値を検討する際には、VGG-19では学習率0.1、Resnet-18では0.03を使用する。
一般的に、k の値が大きいほど、最終的な当りくじの精度が高くなる。
Resnet-18。kの値が5000未満の場合、kが増加するにつれて精度は急速に向上する。この関係は、k = 5000を超えると収穫逓減点に達する。セクション4の実験では、検証精度が最も高くなるk = 20000を選択する。
VGG-19。kの値が5000未満の場合、kが増加するにつれて精度は急速に向上する。この関係は、k = 5000を超えると収穫逓減点に達する。セクション4の実験では、kの値を大きくしてもメリットがほとんどないため、k = 10000を選択する。
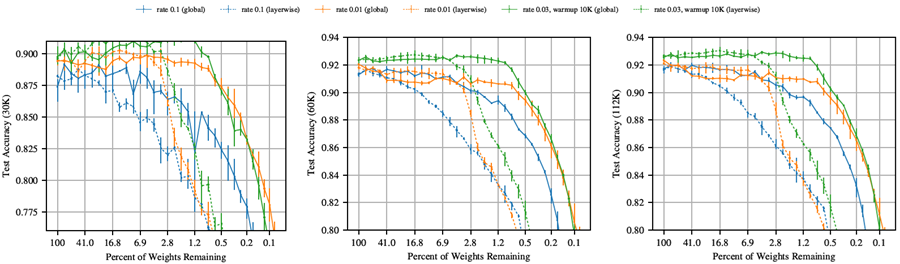
図 38: グローバル (実線) およびレイヤー単位 (破線) のプルーニングを使用して反復的にプルーニングした場合の VGG-19 の検証精度 (30K、60K、112K 反復時)。
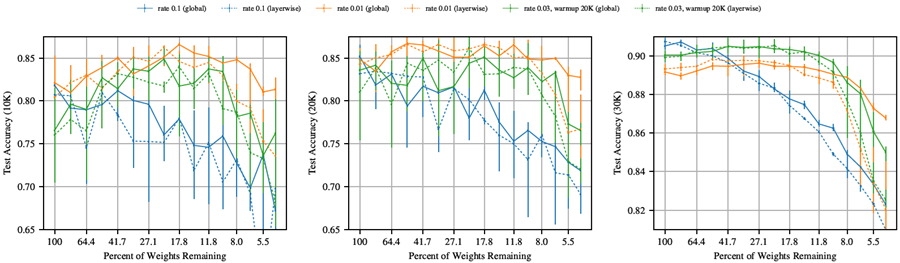
図 39: グローバル (実線) およびレイヤー単位 (破線) のプルーニングを使用して反復的にプルーニングした場合の Resnet-18 の検証精度 (10K、20K、30K 反復時)。
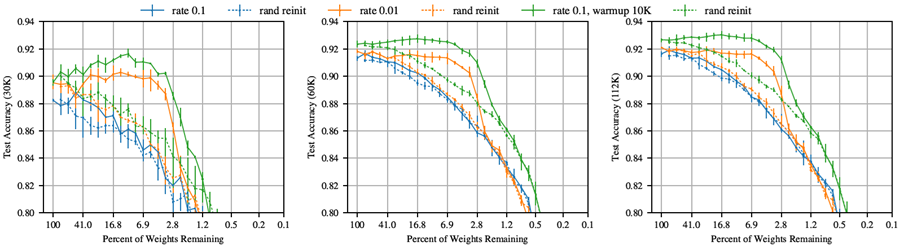
図40: レイヤーワイズプルーニングを適用したVGG-19のテスト精度(3万回、6万回、11万2千回反復時)。これは図7と同じであるが、グローバルプルーニングではなくレイヤーワイズプルーニングを適用している。
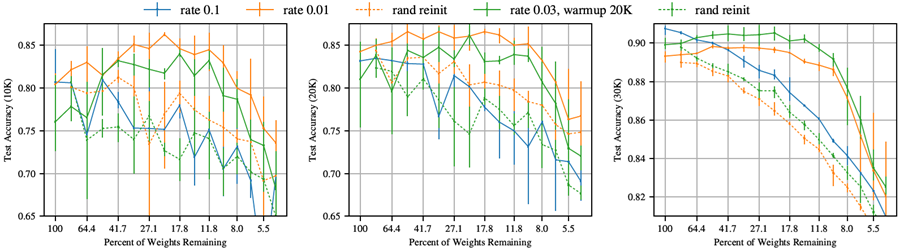
図41: レイヤーワイズプルーニングを適用したResnet-18のテスト精度(1万回、2万回、3万回反復時)。これは、グローバルプルーニングではなくレイヤーワイズプルーニングを適用した点を除いて図8と同じである。
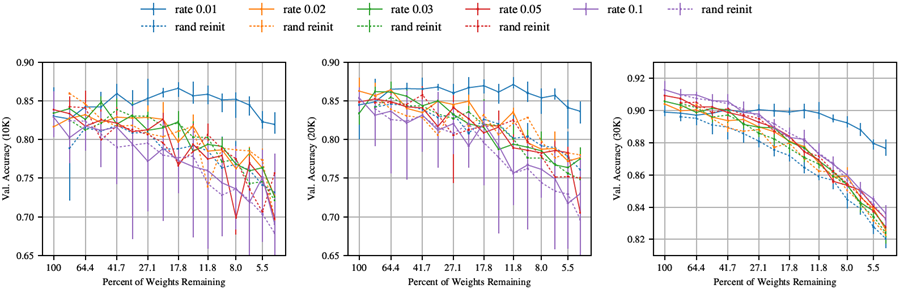
図42: Resnet-18を様々な学習率で反復的に刈り込み、学習させた場合の検証精度(10K、20K、30K反復時)
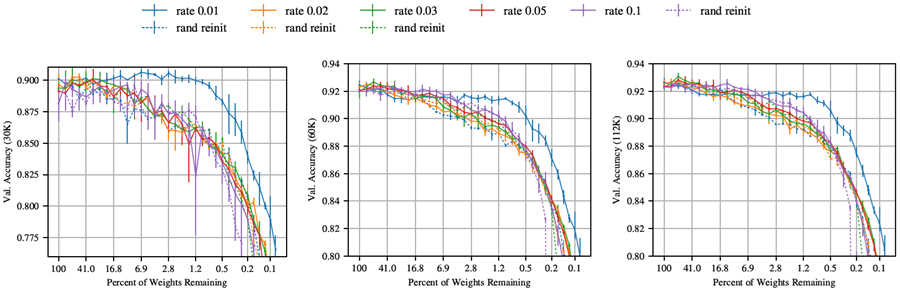
図 43: さまざまな学習率で反復的に枝刈りおよびトレーニングした場合の VGG-19 の検証精度 (30K、60K、112K 反復時)。
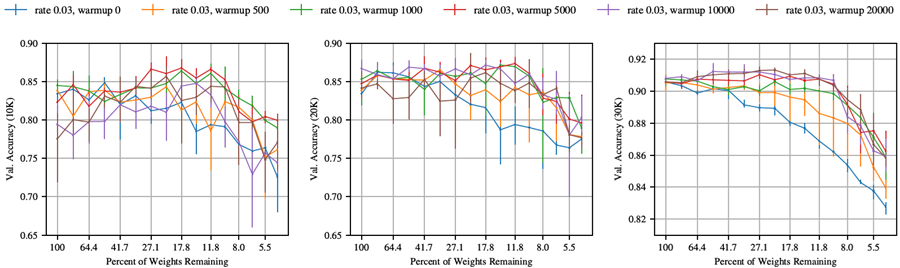
図 44: 学習率 0.03 でさまざまな量のウォームアップを使用して反復的にプルーニングおよびトレーニングした場合の Resnet-18 の検証精度 (10K、20K、30K 反復時)。
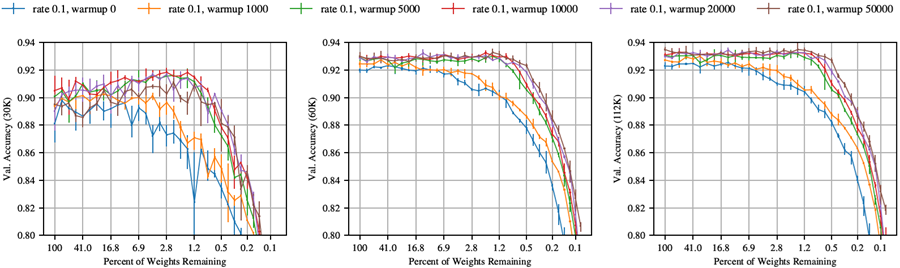
図 45: 学習率 0.1 でさまざまな量のウォームアップを使用して反復的にプルーニングおよびトレーニングした場合の VGG-19 の検証精度 (30K、60K、および 112K 反復時)。